Wetenschap
Het ontsluiten van de belofte van benaderend computergebruik voor AI-versnelling op de chip
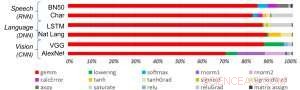
Afbeelding 1. Deep learning-algoritmen bestaan uit een spectrum van bewerkingen. Hoewel matrixvermenigvuldiging dominant is, het optimaliseren van prestatie-efficiëntie met behoud van nauwkeurigheid vereist dat de kernarchitectuur alle hulpfuncties efficiënt ondersteunt. Krediet:IBM
Recente ontwikkelingen in deep learning en exponentiële groei in het gebruik van machine learning in applicatiedomeinen hebben AI-versnelling van cruciaal belang gemaakt. IBM Research heeft een pijplijn van AI-hardwareversnellers gebouwd om aan deze behoefte te voldoen. Op het 2018 VLSI Circuits Symposium, we hebben een multi-TeraOPS-acceleratorkernbouwsteen gepresenteerd die kan worden geschaald over een breed scala aan AI-hardwaresystemen. Deze digitale AI-kern heeft een parallelle architectuur die zorgt voor een zeer hoog gebruik en efficiënte rekenengines die zorgvuldig gebruikmaken van verminderde precisie.
Approximate computing is een centraal uitgangspunt van onze benadering van het benutten van "de fysica van AI", waarin zeer energiezuinige computerwinst wordt behaald door speciaal gebouwde architecturen, aanvankelijk met behulp van digitale berekeningen en later met analoge en in-memory computing.
historisch, berekening is gebaseerd op hoge precisie 64- en 32-bits drijvende-kommaberekeningen. Deze aanpak levert nauwkeurige berekeningen tot op de n-de decimale punt, een nauwkeurigheidsniveau dat essentieel is voor wetenschappelijke computertaken zoals het simuleren van het menselijk hart of het berekenen van de trajecten van de spaceshuttle. Maar hebben we dit nauwkeurigheidsniveau nodig voor veelvoorkomende deep learning-taken? Hebben onze hersenen een afbeelding met hoge resolutie nodig om een familielid te herkennen, of een kat? Wanneer we een tekstthread invoeren om te zoeken, hebben we precisie nodig in de relatieve rangschikking van de 50, 002e meest bruikbare antwoord vs de 50, 003e? Het antwoord is dat veel taken, waaronder deze voorbeelden, kunnen worden bereikt met benaderend computergebruik.
Aangezien volledige precisie zelden vereist is voor veelvoorkomende deep learning-workloads, verminderde precisie is een natuurlijke richting. Computationele bouwstenen met 16-bits precisie-engines zijn 4x kleiner dan vergelijkbare blokken met 32-bits precisie; deze winst in gebiedsefficiëntie wordt een boost in prestaties en energie-efficiëntie voor zowel AI-training als inferencing-workloads. Simpel gezegd, bij benadering, we kunnen numerieke precisie inruilen voor rekenefficiëntie, op voorwaarde dat we ook algoritmische verbeteringen ontwikkelen om de nauwkeurigheid van het model te behouden. Deze benadering vormt ook een aanvulling op andere geschatte computertechnieken, waaronder recent werk waarin nieuwe benaderingen voor trainingscompressie werden beschreven om de communicatie-overhead te verminderen, wat leidt tot een versnelling van 40-200x ten opzichte van bestaande methoden.
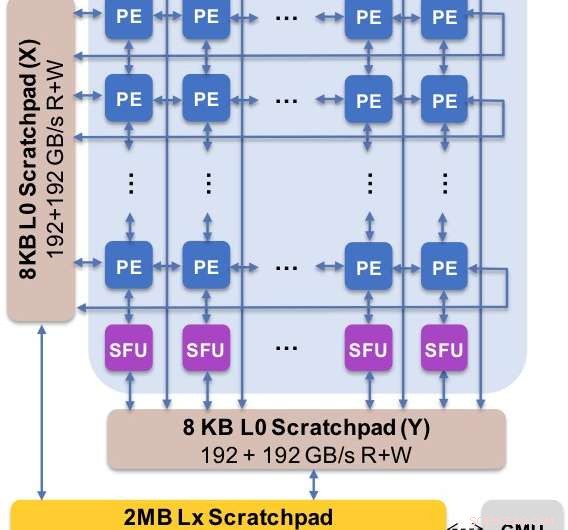
Afbeelding 2. De kernarchitectuur legt de aangepaste gegevensstroom vast met een kladblokhiërarchie. Het verwerkingselement (PE) maakt gebruik van verminderde precisie voor matrixvermenigvuldigingsbewerkingen en sommige activeringsfuncties, terwijl de speciale functie-eenheden (SFU) 32-bits drijvende-kommaprecisie behouden voor de resterende vectorbewerkingen. Krediet:IBM
We presenteerden experimentele resultaten van onze digitale AI-kern op het 2018 Symposium over VLSI Circuits. Het ontwerp van onze nieuwe kern werd beheerst door vier doelstellingen:
- End-to-end prestaties:parallelle berekening, hoog gebruik, hoge databandbreedte
- Nauwkeurigheid van deep learning-modellen:net zo nauwkeurig als implementaties met hoge precisie
- Energie-efficiëntie:het vermogen van applicaties moet worden gedomineerd door rekenelementen
- Flexibiliteit en programmeerbaarheid:maakt afstemming van huidige algoritmen mogelijk, evenals de ontwikkeling van toekomstige deep learning-algoritmen en -modellen
Onze nieuwe architectuur is geoptimaliseerd voor niet alleen matrixvermenigvuldiging en convolutionele kernels, die de neiging hebben om deep learning-berekeningen te domineren, maar ook een spectrum van activeringsfuncties die deel uitmaken van de rekenbelasting van deep learning. Verder, onze architectuur biedt ondersteuning voor native convolutionele bewerkingen, waardoor deep learning-training en inferentietaken op afbeeldingen en spraakgegevens met uitzonderlijke efficiëntie op de kern kunnen worden uitgevoerd.
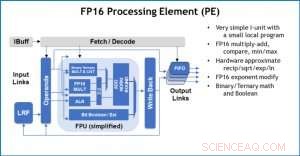
Afbeelding 3. Processing Element (PE) met 16-bit floating point (FP16) mogelijkheden voor matrixvermenigvuldiging, binaire en ternaire wiskunde, activeringsfuncties en Booleaanse bewerkingen. Krediet:IBM
Ter illustratie van hoe de kernarchitectuur is geoptimaliseerd voor een verscheidenheid aan deep learning-functies, Afbeelding 1 toont de uitsplitsing van bewerkingstypen binnen deep learning-algoritmen in een spectrum van toepassingsdomeinen. De dominante matrixvermenigvuldigingscomponenten worden berekend in de kernarchitectuur door gebruik te maken van een aangepaste gegevensstroomorganisatie van de verwerkingselementen die worden getoond in figuren 2 en 3, waar berekeningen met verminderde precisie efficiënt kunnen worden benut, terwijl de overige vectorfuncties (alle niet-rode balken in figuur 1) worden uitgevoerd in ofwel de verwerkingselementen ofwel de speciale functie-eenheden die worden getoond in figuren 3 of 4, afhankelijk van de precisiebehoeften van de specifieke functie.
Op het Symposium, we toonden hardwareresultaten die bevestigen dat deze benadering met één architectuur in staat is tot zowel training als inferentie en modellen in meerdere domeinen ondersteunt (bijv. toespraak, visie, natuurlijke taalverwerking). Terwijl andere groepen wijzen op "piekprestaties" van hun gespecialiseerde AI-chips, maar hebben aanhoudende prestatieniveaus op een klein deel van de piek, we hebben ons gericht op het maximaliseren van duurzame prestaties en gebruik, omdat duurzame prestaties zich direct vertalen in gebruikerservaring en reactietijden.
Onze testchip wordt getoond in Figuur 5. Met behulp van deze testchip, ingebouwde 14LPP-technologie, we hebben met succes zowel training als inferentie gedemonstreerd, in een brede deep learning-bibliotheek, het uitvoeren van alle bewerkingen die vaak worden gebruikt bij deep learning-taken, inclusief matrixvermenigvuldigingen, windingen en verschillende niet-lineaire activeringsfuncties.
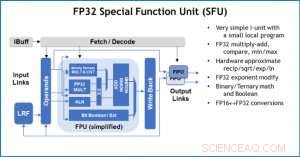
Figuur 4. Special Function Unit (SFU) met 32-bit floating point (FP32) voor bepaalde vectorberekeningen. Krediet:IBM
We highlighted the flexibility and multi-purpose capability of the digital AI core and native support for multiple dataflows in the VLSI paper, but this approach is fully modular. This AI core can be integrated into SoCs, CPUs, or microcontrollers and used for training, inference, or both. Chips using the core can be deployed in the data center or at the edge.
Driven by a fundamental understanding of deep learning algorithms at IBM Research, we expect the precision requirements for training and inference to continue to scale—which will drive quantum efficiency improvements in hardware architectures needed for AI. Stay tuned for more research from our team.
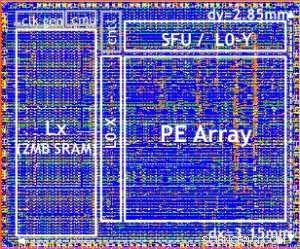
Figure 5. Digital AI Core testchip, based on 14LPP technology, including 5.75M gates, 1.00 flip-flops, 16KB L0 and 16KB of PE local registers. This chip was used to demonstrate both training and inferencing, across a wide range of AI workloads. Credit:IBM
 Nieuwe studie analyseert wereldwijde gevolgen voor het milieu van de verzwakking van de handelsrelatie tussen de VS en China
Nieuwe studie analyseert wereldwijde gevolgen voor het milieu van de verzwakking van de handelsrelatie tussen de VS en China- Het is absoluut noodzakelijk om natuurlijke processen op te nemen om ecologische krachten te benutten en herstel van ecosystemen van koraalriffen te stimuleren
- Indonesische vulkaan in verse uitbarstingen
- De wijnindustrie van de wereld past zich aan de klimaatverandering aan
- Klimaatverandering kan meer sediment en vervuiling opleveren voor de San Francisco Bay-Delta
Hoofdlijnen
- Delen van een dierencel voor kinderen
- Wat is Herschikking in Meiose?
- Wat kan glycolyse stoppen?
- Nieuwe studie brengt prioriteitsgebieden over de hele wereld in kaart om zoogdieren te beschermen
- Bacteriën als pacemaker voor de darm
- Achter de puppy-hondenogen
- Farmacie Onderzoek Onderwerpen
- Hoe biologische antropologie werkt
- Chimpstudie onthult hoe de hersenstructuur onze evolutie heeft gevormd
- Warmtepomp van de volgende generatie biedt meer betaalbare verwarming en koeling
- Hoe u door het Equifax-aanbod voor de schikking van datalekken navigeert

- Een jaar later, EU heeft 145, 000 klachten over gegevenswet

- Kenia lanceert het grootste windpark van Afrika

- Tech-droom leeft nog steeds op TED-bijeenkomst ondanks Facebook-debacle


 Nanonaalden om de capaciteit en robuustheid van digitale geheugens te vergroten
Nanonaalden om de capaciteit en robuustheid van digitale geheugens te vergroten- Hoe de afstand tussen twee parallelle lijnen te berekenen
- Haatmisdrijven tegen LHBT+'ers in achterstandswijken genegeerd
- Video:Staan we op een biljard ton diamanten?
- Binnenkort screening bij jou in de buurt? Blockchain-technologie gaat in première in Cannes
- Amazon om 100 in te huren, 000 werknemers om aan de vraag naar het coronavirus te voldoen
- Toyota houdt Chinese fabrieken gesloten tot 9 februari vanwege virus
- Nieuwe studies vergroten het vertrouwen in NASA's meting van de temperatuur op aarde
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | French | Norway |

-
Wetenschap © https://nl.scienceaq.com
