Wetenschap
Nieuwe methode maakt spraakscheiding van hoge kwaliteit mogelijk
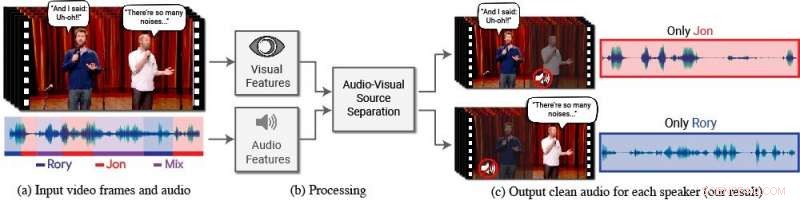
Een nieuw model isoleert en verbetert de spraak van gewenste sprekers in een video. (a) De input is een video (frames + audiotrack) met een of meer mensen aan het woord, waar de spraak van belang wordt gestoord door andere sprekers en/of achtergrondgeluid. (b) Zowel audio- als visuele kenmerken worden geëxtraheerd en ingevoerd in een gezamenlijk audiovisueel spraakscheidingsmodel. (c) De uitvoer is een ontleding van het ingevoerde audiospoor in zuivere spraaksporen, één voor elke persoon die in de video wordt gedetecteerd. De spraak van specifieke mensen wordt versterkt in de video's terwijl al het andere geluid wordt onderdrukt. Het nieuwe model is getraind met behulp van duizenden uren aan videosegmenten uit de nieuwe dataset van het team, AVSpraak, die openbaar zal worden gemaakt. Credits:Auteurs/Google Videobeelden:met dank aan Team Coco/CONAN
Mensen hebben een natuurlijk talent om zich te concentreren op wat een enkele persoon zegt, zelfs als er concurrerende gesprekken op de achtergrond zijn of andere storende geluiden. Bijvoorbeeld, mensen kunnen vaak verstaan wat iemand in een druk restaurant zegt, tijdens een luidruchtig feest, of tijdens het kijken naar televisiedebatten waar meerdere experts door elkaar praten. Daten, het was een moeilijke taak om dit natuurlijke menselijke vermogen om spraak te isoleren op een computationele en nauwkeurige manier na te bootsen.
"Computers worden steeds beter in het begrijpen van spraak, maar nog steeds aanzienlijke moeite hebben met het verstaan van spraak wanneer meerdere mensen samen praten of wanneer er veel lawaai is, " zegt Ariël Efrat, een doctoraat kandidaat aan de Hebreeuwse Universiteit van Jeruzalem-Israël en hoofdauteur van het onderzoek. (Ephrat ontwikkelde het nieuwe model tijdens zijn stage bij Google in de zomer van 2017.) "Wij mensen weten op natuurlijke wijze spraak te verstaan in dergelijke omstandigheden, maar we willen dat computers het net zo goed kunnen als wij, misschien zelfs beter."
Hiertoe, Ephrat en zijn collega's bij Google hebben een nieuw audiovisueel model ontwikkeld voor het isoleren en verbeteren van de spraak van gewenste sprekers in een video. Het diepe netwerkgebaseerde model van het team bevat zowel visuele als auditieve signalen om elke spreker in elke video te isoleren en te verbeteren, zelfs in uitdagende real-world scenario's, zoals videoconferenties, waar meerdere deelnemers vaak tegelijk praten, en luidruchtige bars, die een verscheidenheid aan achtergrondgeluiden kan bevatten, muziek, en concurrerende gesprekken.
Het team, waaronder Google's Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, en Michael Rubinstein, zullen hun werk presenteren op SIGGRAPH 2018, gehouden van 12-16 augustus in Vancouver, Brits-Columbia. De jaarlijkse conferentie en tentoonstelling toont 's werelds toonaangevende professionals, academici, en creatieve geesten in de voorhoede van computergraphics en interactieve technieken.
In dit werk, de onderzoekers concentreerden zich niet alleen op auditieve signalen om spraak te scheiden, maar ook op visuele signalen in de video, d.w.z. de lipbewegingen van het onderwerp en mogelijk andere gezichtsbewegingen die kunnen bijdragen aan wat hij of zij zegt. De vergaarde visuele kenmerken worden gebruikt om de audio te "focussen" op een enkel onderwerp dat aan het woord is en om de kwaliteit van spraakscheiding te verbeteren.
Om hun gezamenlijke audiovisuele model te trainen, Ephrat en medewerkers hebben een nieuwe dataset samengesteld, "AVSpraak, " bestaande uit duizenden YouTube-video's en andere online videosegmenten, zoals TED-talks, instructievideo's, en hoogwaardige lezingen. Van AVSpeech, de onderzoekers genereerden een trainingsset van zogenaamde "synthetische cocktailparty's" - mengsels van gezichtsvideo's met zuivere spraak en andere spraakaudiotracks met achtergrondgeluid. Om spraak uit deze video's te isoleren, de gebruiker hoeft alleen het gezicht op te geven van de persoon in de video wiens audio moet worden uitgekozen.
In meerdere voorbeelden die in het document worden beschreven, getiteld "Looking to Listen at the Cocktail Party:A Speaker-ondependent Audio-Visual Model for Speech Separation, " de nieuwe methode leverde superieure resultaten op in vergelijking met bestaande methoden met alleen audio op pure spraakmengsels, en aanzienlijke verbeteringen in het leveren van heldere audio van mengsels met overlappende spraak en achtergrondgeluid in realistische scenario's. Hoewel de focus van het werk ligt op spraakscheiding en -verbetering, de nieuwe methode van het team kan ook worden toegepast op automatische spraakherkenning (ASR) en videotranscriptie, d.w.z. ondertitelingsmogelijkheden op streaming video's en tv. Bij een demonstratie, het nieuwe gezamenlijke audiovisuele model produceerde nauwkeuriger bijschriften in scenario's waarbij twee of meer sprekers betrokken waren.
Eerst verrast door hoe goed hun methode werkte, de onderzoekers zijn enthousiast over het toekomstige potentieel.
"We hebben spraakscheiding nog niet eerder 'in-the-wild' met zo'n kwaliteit gezien. Daarom zien we een opwindende toekomst voor deze technologie, " merkt Ephrat op. "Er is meer werk nodig voordat deze technologie in consumentenhanden terechtkomt, maar met de veelbelovende voorlopige resultaten die we hebben laten zien, we kunnen zeker zien dat het in de toekomst een reeks toepassingen ondersteunt, zoals video-ondertiteling, videovergaderen, en zelfs verbeterde hoortoestellen als zulke toestellen gecombineerd kunnen worden met camera's."
De onderzoekers onderzoeken momenteel de mogelijkheden om het in verschillende Google-producten op te nemen.
 Nieuw isolatiemateriaal zorgt voor een efficiëntere elektriciteitsdistributie
Nieuw isolatiemateriaal zorgt voor een efficiëntere elektriciteitsdistributie- Een wondermiddel voor de chemische omzetting van kooldioxide
- Nieuwe katalysator helpt koolstofdioxide om te zetten in brandstof
- Tweerichtingssymmetrie in de moleculaire fysica
- Eenvoudige methode voorgesteld voor microfabricage op niet-vlakke substraten
- De eerste botsing tussen Indiase en Aziatische continentale
- Waarom voeren mannelijke kardinalen vrouwelijke kardinalen?
- De stilte:wereldwijde windsnelheden nemen af sinds 1960
- Geologen graven in de mysterieuze kloof van Grand Canyons in de tijd
- Broeikaseffect van wolken speelt rol bij het ontstaan van tropische stormen
Hoofdlijnen
- Uitwerpselen van verstrikte Noord-Atlantische walvissen onthullen torenhoge stressniveaus
- Kunnen genetisch gemodificeerde muggen malaria uitroeien?
- Studie belicht botanische vooroordelen
- Gist kan worden ontwikkeld om eiwitgeneesmiddelen te maken
- Stichting om speciaal reservaat te creëren voor albino orang-oetan
- Behoefte aan snelheid maakt genoombewerking efficiënt, zo niet beter
- Bereidheid om risico's te nemen - een persoonlijkheidskenmerk
- Genen die mensen scheiden van fruitvliegen gevonden
- Parasitaire wormen wachten niet om te worden opgeslokt door nieuwe gastheren
- Hersenachtige computerchips kunnen privacyproblemen en broeikasgasemissies aanpakken

- Hacks dwarsbomen door te denken als de mensen erachter

- Privacy wordt een verkoopargument op tech show

- Voor $ 10 vergoeding, startup biedt onbeperkt bellen en sms'en

- Singapore zegt dat hackers 1,5 miljoen gezondheidsdossiers hebben gestolen in een record cyberaanval


 SpaceX-vrachtschip keert terug naar aarde
SpaceX-vrachtschip keert terug naar aarde- Economen ontdekken dat de ecologische voetafdruk groeit met het ouderschap
- Hele huizen weggevaagd door Irma op Bransons eiland
- ReNature lanceert nieuwe toolkit voor op de natuur gebaseerde oplossingen
- Bosbranden verbrandden een vijfde van het Australische bos:studie
- Stemmen van de rede? Studie verbindt akoestische correlaties, geslacht tot vocale aantrekkingskracht
- Kooldioxide uit schoorstenen schrobben voor schonere industriële emissies
- EU-uitspraak tegen Google biedt kansen, rivaal zegt
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
