Wetenschap
Chemici laten zien hoe vooringenomenheid kan opduiken in de resultaten van machine learning-algoritmen
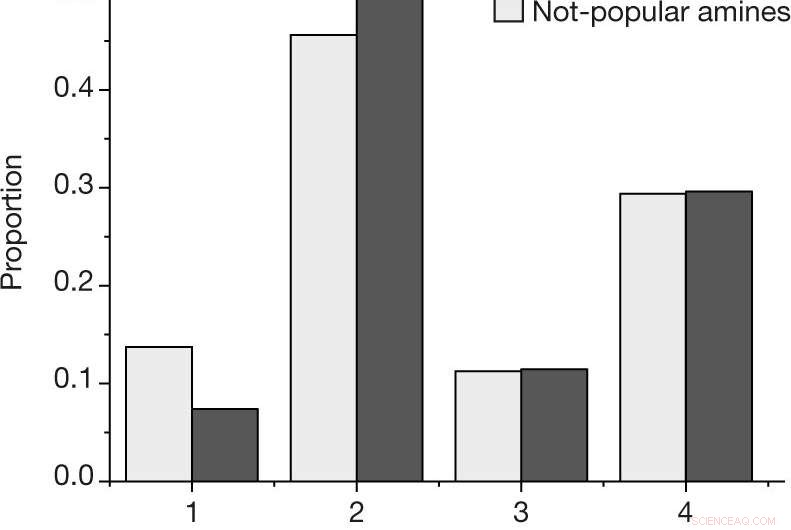
een, De verhouding naar uitkomst voor elke reactie, met behulp van de uitkomstschaal beschreven in Methoden, voor de populaire en niet-populaire amines in de door mensen geselecteerde dataset. B, Geschatte kans op het waarnemen van ten minste één succesvolle reactie (uitkomst 4) of mislukking (uitkomst 1, 2 en 3) voor een gegeven amine, voor de N =27 populaire en N =28 niet-populaire amines in de door mensen geselecteerde dataset. Centrumwaarden geven het waargenomen deel van de uitkomsten aan. Foutbalken geven een bootstrap-schatting van de standaarddeviatie aan. Credit: Natuur (2019). DOI:10.1038/s41586-019-1540-5
Een team van materiaalwetenschappers van Haverford College heeft aangetoond hoe menselijke vooroordelen in gegevens de resultaten kunnen beïnvloeden van algoritmen voor machinaal leren die worden gebruikt om nieuwe reagentia te voorspellen voor gebruik bij het maken van gewenste producten. In hun artikel gepubliceerd in het tijdschrift Natuur , de groep beschrijft het testen van een machine learning-algoritme met verschillende soorten datasets en wat ze hebben gevonden.
Een van de meer bekende toepassingen van machine learning-algoritmen is gezichtsherkenning. Maar er zijn mogelijke problemen met dergelijke algoritmen. Een voorbeeld van zo'n probleem doet zich voor wanneer een gezichtsalgoritme dat bedoeld is om een persoon tussen vele gezichten te zoeken, is getraind met mensen van slechts één ras. In deze nieuwe poging de onderzoekers vroegen zich af of vooringenomenheid, onopzettelijk of anderszins, zou kunnen opduiken in machine learning-algoritmeresultaten die worden gebruikt in chemietoepassingen die zijn ontworpen om naar nieuwe producten te zoeken.
Dergelijke algoritmen gebruiken gegevens die de ingrediënten beschrijven van reacties die resulteren in de creatie van een nieuw product. Maar de gegevens waarop het systeem is getraind, kunnen een grote impact hebben op de resultaten. De onderzoekers merken op dat momenteel dergelijke gegevens worden verkregen uit gepubliceerde onderzoeksinspanningen, wat betekent dat ze meestal door mensen worden gegenereerd. Ze merken op dat de gegevens van dergelijke inspanningen door de onderzoekers zelf kunnen zijn gegenereerd, of door andere onderzoekers die aan afzonderlijke inspanningen werken. Gegevens kunnen zelfs afkomstig zijn van een enkele persoon die simpelweg uit het geheugen vertelt, of op voorstel van een professor, of een afgestudeerde student met een briljant idee. Het punt is, de gegevens kunnen bevooroordeeld zijn wat betreft de achtergrond van de bron.
In deze nieuwe poging de onderzoekers wilden weten of dergelijke vooroordelen een impact kunnen hebben op de resultaten van algoritmen voor machinaal leren die worden gebruikt voor scheikundige toepassingen. Er achter komen, ze keken naar een specifieke set materialen die vanadiumboraten met amine-matrijs worden genoemd. Wanneer ze met succes worden gesynthetiseerd, kristallen vormen - een gemakkelijke manier om te bepalen of een reactie succesvol was.
Het experiment bestond uit het trainen van een machine learning-algoritme op gegevens rond de synthese van vanadiumboraten, en vervolgens het systeem programmeren om zijn eigen systeem te maken. Sommige van de door de onderzoekers verzamelde gegevens waren door mensen gegenereerd, en een deel ervan werd willekeurig verzameld. Ze melden dat het algoritme dat op de willekeurige gegevens was getraind, het beter deed in het vinden van manieren om de vanadiumboraten te synthetiseren dan wanneer het gegevens gebruikte die door mensen waren gegenereerd. Ze beweren dat dit een duidelijke vooringenomenheid vertoont in de gegevens die door mensen zijn gemaakt.
© 2019 Wetenschap X Netwerk
 Wat is een Superscript in een chemische formule?
Wat is een Superscript in een chemische formule? - Superieure bio-inkt voor 3D-printen pionier
- Op boraat gebaseerde passiveringslagen maken omkeerbare calciumbatterijen mogelijk
- Ammoniaksynthese door elektroreductie van stikstof op zwarte fosfor nanosheets
- Wetenschappers onderzoeken de structuur van een sleutelgebied van telomerase-eiwit met een lange levensduur
- Luchtvervuiling gekoppeld aan autisme:studie
- Hoe de variaties in de waterkwaliteit in tijd en tijd worden beïnvloed door hydrologische omstandigheden in het Dongting-meer
- Dieren die leven op gletsjers en ijsbergen
- Het magnetisch veld van de aarde ontrafelen
- Glazige menagerie van deeltjes in strandzand bij Hiroshima is afvalafval:studie
Hoofdlijnen
- 6 veelvoorkomende hallucinaties en wat ze ons vertellen
- Wildlife betaalt de prijs van illegale begrazing in Kenia
- Vergeten is niet altijd slecht - het helpt ons betere beslissingen te nemen
- Welke soort weefsel geeft de meeste tijd in interfase?
- Controversiële onkruidverdelger houdt EU in de knoop (Update)
- Wat weefsel zacht en toch zo taai maakt?
- Hoe wordt een zuivere cultuur direct voorbereid?
- Morfogenese en de ontwikkeling van levende vormen
- Het is onwaarschijnlijk dat de jacht op trofeeën de evolutie beïnvloedt
- Microben uit vulkanische openingen in de zee onthullen hoe mensen zich aanpasten aan een veranderende atmosfeer
- High-tech gel helpt bij het afleveren van medicijnen
- Beeldvormingstechniek geeft katalytische 2D-materiaaltechniek een beter zicht
- Combinatie van knoflook en fluor is veelbelovend als medicamenteuze therapie

- Dagelijks gebruik voor waterstof


 Field Trip Ideas voor High School Chemistry
Field Trip Ideas voor High School Chemistry - Nieuw raamwerk verklaart tegenstrijdige schattingen van wereldwijde temperatuurstijgingen
- De duisternis aan het einde van de tunnel
- Zelfrijdende auto's bieden nieuwe vormen van controle - geen wonder dat regeringen enthousiast zijn
- Computerondersteund ontwerp aanpassen
- Manfred Eigen, 1967 Nobelprijswinnaar scheikunde, sterft op 91
- Hoe factor X kwadraat min 2
- Ruslands eerste drijvende kerncentrale ter wereld arriveert in haven
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | Spanish |

-
Wetenschap © https://nl.scienceaq.com
