Wetenschap
Vroege inspanningen op weg naar betrouwbaar leren van kwantummachines
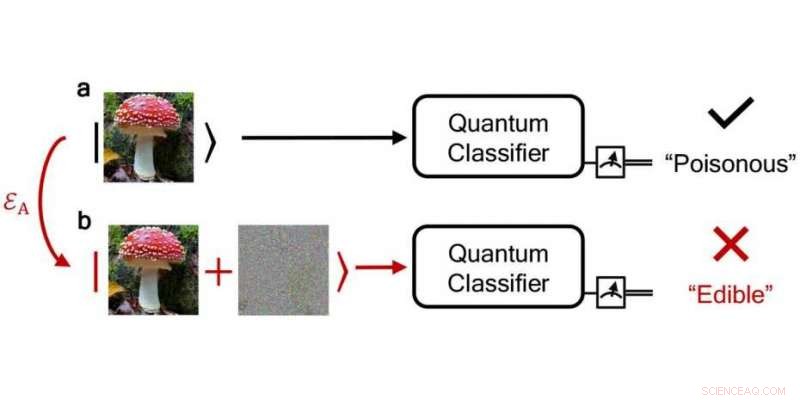
Een betrouwbaar kwantumclassificatie-algoritme classificeert een giftige paddenstoel correct als "giftig", terwijl een luidruchtige, verstoord classificeert men het ten onrechte als "eetbaar". Krediet:npj Quantum Information / DS3Lab ETH Zürich
Iedereen die paddenstoelen verzamelt, weet dat je de giftige en de niet-giftige beter uit elkaar kunt houden. In dergelijke "classificatieproblemen, " die vereisen dat bepaalde objecten van elkaar worden onderscheiden en de objecten die we zoeken aan bepaalde klassen moeten worden toegewezen door middel van kenmerken, computers bieden al nuttige ondersteuning.
Intelligente machine learning-methoden kunnen patronen of objecten herkennen en deze automatisch uit datasets halen. Bijvoorbeeld, ze konden die foto's uit een fotodatabase halen waarop niet-giftige paddenstoelen te zien waren. Vooral bij zeer grote en complexe datasets, machine learning kan waardevolle resultaten opleveren die mensen zonder veel tijd en moeite niet zouden kunnen bepalen. Echter, voor bepaalde rekentaken, zelfs de snelste computers die tegenwoordig beschikbaar zijn, bereiken hun limieten. Dit is waar de grote belofte van kwantumcomputers in het spel komt - op een dag, ze konden supersnelle berekeningen uitvoeren die klassieke computers niet in een bruikbare tijdsperiode kunnen oplossen.
De reden voor deze 'kwantumoverheersing' ligt in de natuurkunde:kwantumcomputers berekenen en verwerken informatie door gebruik te maken van bepaalde toestanden en interacties die plaatsvinden binnen atomen of moleculen of tussen elementaire deeltjes.
Het feit dat kwantumtoestanden superponeren en verstrengelen, creëert een basis die kwantumcomputers toegang geeft tot een fundamenteel rijkere reeks verwerkingslogica. Bijvoorbeeld, in tegenstelling tot klassieke computers, kwantumcomputers rekenen niet met binaire codes of bits, die informatie alleen verwerken als 0 of 1, maar met kwantumbits of qubits, die overeenkomen met de kwantumtoestanden van deeltjes. Het cruciale verschil is dat qubits niet slechts één toestand - 0 of 1 - per rekenstap kunnen realiseren, maar ook een superpositie van beide. Deze meer algemene methoden van informatieverwerking zorgen op hun beurt voor een drastische rekensnelheid bij bepaalde problemen.
Klassieke wijsheid vertalen naar het kwantumrijk
Deze snelheidsvoordelen van kwantumcomputing zijn ook een kans voor machine learning-applicaties - per slot van rekening kwantumcomputers kunnen de enorme hoeveelheden gegevens berekenen die methoden voor machinaal leren nodig hebben om de nauwkeurigheid van hun resultaten veel sneller te verbeteren dan klassieke computers.
Echter, om het potentieel van kwantumcomputers echt te benutten, het is noodzakelijk om klassieke machinale leermethoden aan te passen aan de eigenaardigheden van kwantumcomputers. Bijvoorbeeld, algoritmen, d.w.z., de wiskundige regels die beschrijven hoe een klassieke computer een bepaald probleem oplost, voor kwantumcomputers anders geformuleerd moeten worden. Het ontwikkelen van goed werkende kwantumalgoritmen voor machine learning is niet helemaal triviaal, omdat er onderweg nog een aantal hindernissen te overwinnen zijn.
Aan de ene kant, dit komt door de kwantumhardware. Bij ETH Zürich, onderzoekers hebben momenteel kwantumcomputers die werken met maximaal 17 qubits (zie "ETH Zürich en PSI hebben Quantum Computing Hub gevonden" van 3 mei 2021). Echter, als kwantumcomputers op een dag hun volledige potentieel zullen realiseren, ze hebben misschien duizenden tot honderdduizenden qubits nodig.
Quantumruis en de onvermijdelijkheid van fouten
Een uitdaging waarmee kwantumcomputers worden geconfronteerd, betreft hun kwetsbaarheid voor fouten. De huidige kwantumcomputers werken met een zeer hoog geluidsniveau, aangezien fouten of storingen bekend zijn in vakjargon. Voor de American Physical Society, deze ruis is "het grootste obstakel voor het opschalen van kwantumcomputers." Er bestaat geen alomvattende oplossing voor zowel het corrigeren als het beperken van fouten. Er is nog geen manier gevonden om foutloze kwantumhardware te produceren, en kwantumcomputers met 50 tot 100 qubits zijn te klein om correctiesoftware of -algoritmen te implementeren.
Tot op zekere hoogte, fouten in quantum computing zijn in principe onvermijdelijk, omdat de kwantumtoestanden waarop de concrete rekenstappen zijn gebaseerd, alleen met waarschijnlijkheden kunnen worden onderscheiden en gekwantificeerd. Wat kan worden bereikt, anderzijds, zijn procedures die de omvang van geluid en verstoringen zodanig beperken dat de berekeningen toch betrouwbare resultaten opleveren. Computerwetenschappers noemen een betrouwbaar functionerende rekenmethode "robuust, "en in dit verband spreek ook van de noodzakelijke "fouttolerantie".
Dit is wat de onderzoeksgroep onder leiding van Ce Zhang, ETH professor computerwetenschappen en lid van het ETH AI Center, heeft onlangs verkend, op de een of andere manier "per ongeluk" tijdens een poging om te redeneren over de robuustheid van klassieke distributies met als doel betere machine learning-systemen en platforms te bouwen. Samen met professor Nana Liu van de Shanghai Jiao Tong University en met professor Bo Li van de University of Illinois in Urbana, ze hebben een nieuwe aanpak ontwikkeld die de robuustheid van bepaalde op kwantum gebaseerde machine learning-modellen bewijst, waarvoor de kwantumberekening gegarandeerd betrouwbaar is en het resultaat correct is. De onderzoekers hebben hun aanpak gepubliceerd, dat is een van de eerste in zijn soort, in het wetenschappelijke tijdschrift npj Quantum-informatie .
Bescherming tegen fouten en hackers
"Toen we ons realiseerden dat kwantumalgoritmen, zoals klassieke algoritmen, zijn gevoelig voor fouten en verstoringen, we vroegen ons af hoe we deze bronnen van fouten en verstoringen voor bepaalde machine learning-taken kunnen inschatten, en hoe we de robuustheid en betrouwbaarheid van de gekozen methode kunnen garanderen, " zegt Zhikuan Zhao, een postdoc in de groep van Ce Zhang. "Als we dit weten, we kunnen vertrouwen op de rekenresultaten, zelfs als ze luidruchtig zijn."
De onderzoekers onderzochten deze vraag met behulp van kwantumclassificatie-algoritmen als voorbeeld - per slot van rekening fouten in classificatietaken zijn lastig omdat ze de echte wereld kunnen beïnvloeden, bijvoorbeeld als giftige paddenstoelen als niet-toxisch werden geclassificeerd. Misschien wel het belangrijkste, met behulp van de theorie van het testen van kwantumhypothesen - geïnspireerd door het recente werk van andere onderzoekers bij het toepassen van hypothesetesten in de klassieke setting - waarmee kwantumtoestanden kunnen worden onderscheiden, de ETH-onderzoekers bepaalden een drempel waarboven de toewijzingen van het kwantumclassificatie-algoritme gegarandeerd correct zijn en de voorspellingen robuust.
Met hun robuustheidsmethode, kunnen de onderzoekers zelfs nagaan of de classificatie van een foutieve, luidruchtige invoer levert hetzelfde resultaat op als een schone, geruisloze ingang. Uit hun bevindingen, de onderzoekers hebben ook een beschermingsschema ontwikkeld dat kan worden gebruikt om de fouttolerantie van een berekening te specificeren, ongeacht of een fout een natuurlijke oorzaak heeft of het gevolg is van manipulatie door een hackaanval. Hun robuustheidsconcept werkt voor zowel hackaanvallen als natuurlijke fouten.
"De methode kan ook worden toegepast op een bredere klasse van kwantumalgoritmen, " zegt Maurice Weber, een promovendus bij Ce Zhang en de eerste auteur van de publicatie. Omdat de impact van fouten in quantum computing toeneemt naarmate de systeemgrootte toeneemt, hij en Zhao doen nu onderzoek naar dit probleem. "We zijn optimistisch dat onze robuustheidsvoorwaarden nuttig zullen blijken, bijvoorbeeld, in combinatie met kwantumalgoritmen die zijn ontworpen om de elektronische structuur van moleculen beter te begrijpen."
 Team ontwikkelt een elektrochemische methode om uranium te winnen, en mogelijk andere metaalionen, van oplossing
Team ontwikkelt een elektrochemische methode om uranium te winnen, en mogelijk andere metaalionen, van oplossing- De geur van oude boeken zou kunnen helpen ze te bewaren
- Neutronen verbeteren de lasintegriteit van funderingen van onderwaterwindturbines
- Vergeet het ontdooien van je auto in een ijzig tempo:nieuw onderzoek vertienvoudigt het proces
- Wetenschappers ontdekken natuurlijke plantaardige conserveermiddelen
Hoofdlijnen
- The Krebs Cycle Made Easy
- Verschil tussen recombinant DNA en genetische manipulatie
- Verschillen en overeenkomsten tussen Unicellular & Cellular
- Kan de wetenschap verklaren waarom we zoenen met onze ogen dicht?
- Op weg naar pesticidebewaking
- Feiten over lipiden
- Wat zijn de vier belangrijkste methoden voor het produceren van ATP?
- Is genie genetisch?
- Het overdrachtspotentieel van vliegen kan groter zijn dan gedacht, onderzoekers zeggen:
- Kwantumverstrengeling gebruiken om eiwitten te bestuderen
- Ultrasnelle beeldvorming onthult het bestaan van polarons

- Onderzoekers observeren voor het eerst vertakte lichtstroom

- Energizer Watt-Hour Batterij Specificaties

- Wetenschappers ontwikkelen tomografische methode om de toestand van solitaire elektronen te visualiseren

 Hoe een parabool op te lossen
Hoe een parabool op te lossen - De toekomst van boodschappen doen:sneller, goedkoper, kleiner
- iOS 13.4-release brengt VPN-bescherming in gevaar
- Bosbranden kunnen het drinkwater vervuilen. Dat baart sommigen zorgen in de heuvels boven Santa Cruz
- Nieuwe DNA-database bij Rutgers-Camden om forensische wetenschap te versterken
- Wat is het doel van de fibreuze capsule?
- Zout meer, vijvers borrelen mogelijk onder de zuidpool van Mars
- Voordelen en nadelen van het bouwen van dammen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | Italian |

-
Wetenschap © https://nl.scienceaq.com
