Wetenschap
Quantum auto-encoders om kwantummetingen ongedaan te maken
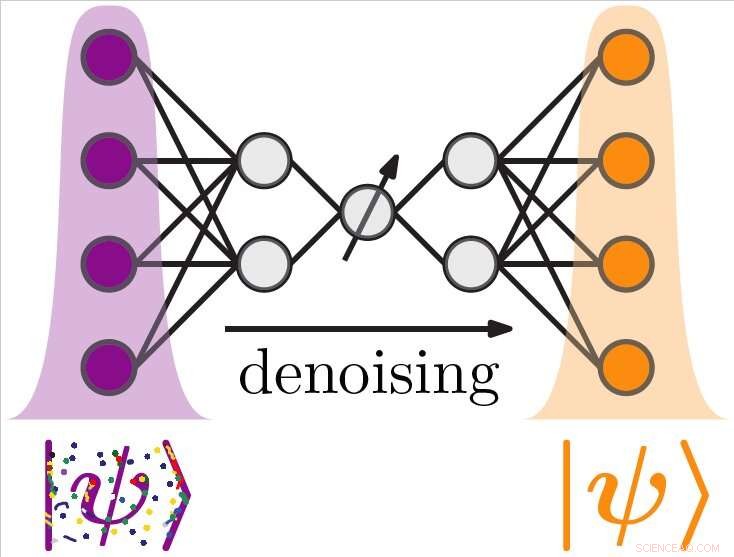
Credit:Bondarenko &Feldmann.
Veel onderzoeksgroepen wereldwijd proberen momenteel instrumenten te ontwikkelen om zeer nauwkeurige metingen te verzamelen, zoals atoomklokken of gravimeters. Sommige van deze onderzoekers hebben geprobeerd dit te bereiken met behulp van verstrengelde kwantumtoestanden, die een hogere gevoeligheid voor hoeveelheden hebben dan klassieke of niet-verstrengelde toestanden.
Door deze hoge gevoeligheid echter, kwantumverstrengelde toestanden zijn ook gevoeliger voor het oppikken van ruis (d.w.z. niet-gerelateerde signalen) tijdens het verzamelen van metingen. Dit kan de ontwikkeling van nauwkeurige en betrouwbare kwantumverbeterde metrologische apparaten belemmeren.
Om deze beperking te overwinnen, twee onderzoekers van de Leibniz Universität Hannover in Duitsland hebben onlangs algoritmen voor het leren van kwantummachines ontwikkeld die kunnen worden gebruikt om kwantumgegevens ongedaan te maken. Deze algoritmen, gepresenteerd in een paper gepubliceerd in Fysieke beoordelingsbrieven , zou kunnen helpen om betrouwbaardere gegevens te produceren met behulp van kwantumklokken of andere meetinstrumenten op basis van verstrengelde kwantumtoestanden.
Dmytro Bondarenko, een van de bij het onderzoek betrokken onderzoekers, had al gewerkt aan een nieuw algoritme op basis van quantum machine learning onder supervisie van professor Tobias Osborne aan de Leibniz Universität, Hanover. In deze nieuwe studie Bondarenko en zijn collega Polina Feldmann gingen op zoek naar de haalbaarheid van het gebruik van dit algoritme om gegevens die door kwantumversterkte instrumenten zijn verzameld, te ongedaan maken.
"Quantum machine learning is een veelbelovend onderwerp, omdat het de veelzijdigheid van machine learning kan combineren met de kracht van kwantumalgoritmen, " Bondarenko en Feldmann vertelden Phys.org via e-mail. "Machine learning is een alomtegenwoordige methode voor gegevensanalyse."
Net als traditionele algoritmen voor machine learning, algoritmen voor het leren van kwantummachines zijn afhankelijk van een reeks variatieparameters die moeten worden geoptimaliseerd voordat een algoritme kan worden gebruikt om gegevens te analyseren. Om de juiste parameters te leren, het algoritme moet eerst worden getraind op gegevens met betrekking tot de taak waarvoor het is ontworpen (bijv. patroonherkenning, afbeelding classificatie, enzovoort.).
"Als we zeggen kwantum machine learning, we bedoelen dat de invoer en de uitvoer van het algoritme kwantumtoestanden zijn, bijvoorbeeld, van een aantal qubits (kwantumbits), die kan worden gerealiseerd, bijvoorbeeld, met behulp van supergeleiders, Bondarenko en Feldmann zeiden. "Het algoritme dat de invoerstatus in kaart brengt bij de uitvoerstatus, is bedoeld om op een kwantumcomputer te worden geïmplementeerd. De variatieparameters, die geoptimaliseerd moeten worden, zijn klassieke parameters van de transformaties die op de kwantumcomputer worden uitgevoerd."
De twee onderzoekers wilden testen of het eerder door Bondarenko ontwikkelde quantummachine-leunend algoritme, Osborne en hun andere collega's kunnen worden gebruikt om gegevens op te schonen die zijn verzameld met behulp van kwantum-verbeterde metrologietools. Dit leidde uiteindelijk tot de ontwikkeling van de kwantumauto-encoders die in hun recente paper werden geïntroduceerd.
"Stel dat je een kwantumexperiment hebt dat je een aantal luidruchtige kwantumtoestanden geeft, Bondarenko en Feldmann legden het uit. "Veronderstel verder dat je een kwantumcomputer hebt die deze toestanden kan verwerken. Onze autoencoder is een algoritme dat de kwantumcomputer vertelt hoe de lawaaierige kwantumtoestanden van het experiment moeten worden getransformeerd om ze ongedaan te maken."
Als eerste stap in hun onderzoek, Bondarenko en Feldmann hebben hun algoritmen geoptimaliseerd, hen te trainen om kwantumgegevens effectief te deniseren. Omdat referentietoestanden zonder ruis moeilijk te verkrijgen zijn of experimenteel niet beschikbaar zijn, gebruikten de onderzoekers een truc die vaak wordt gebruikt bij het optimaliseren van klassieke autoencoders, die een soort onbewaakte algoritmen voor machine learning zijn.
"De truc is dat het algoritme zo is geschreven dat het de informatie op de weg van de invoer naar de uitvoerstatus moet verminderen, "Zeiden Bondarenko en Feldmann. "Nu, het cijfer van verdienste wordt gedefinieerd als de gelijkenis van de status die door de autoencoder wordt verwerkt en een andere ruisstatus van uw experiment. Om deze toestanden zo gelijk mogelijk te maken, de autoencoder moet de informatie behouden die voor beide toestanden gelijk is (hun gemeenschappelijke geruisloze oorsprong), terwijl het geluid wordt weggegooid, die, in elke staat die voortkomt uit je experiment, is anders."
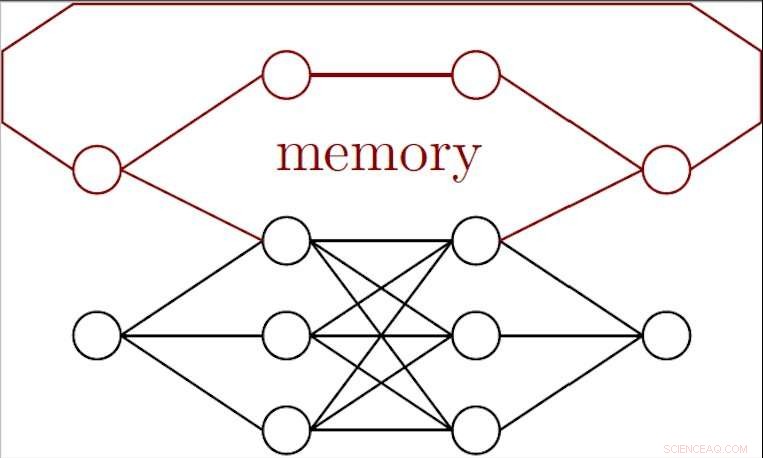
Figuur waarin de structuur van een terugkerende QNN wordt geschetst. Credit:Bondarenko &Feldmann.
De onderzoekers hebben talloze simulaties uitgevoerd waarin ze luidruchtige verstrengelde kwantumtoestanden produceerden. Eerst, ze gebruikten deze 'experimentele' outputs om de variatieparameters van de autoencoder te optimaliseren. Toen deze opleidingsfase eenmaal was voltooid, ze waren in staat om de prestaties van hun auto-encoders te evalueren bij het ruisonderdrukken van kwantummetingen.
"Het mooie van onze aanpak is de algemeenheid, "Zeggen Bondarenko en Feldmann. "Je hoeft niet van tevoren te weten hoe de output van je experiment eruitziet, ook hoeft u uw geluidsbronnen niet te karakteriseren. De ruisonderdrukking werkt zelfs als uw experimentele uitvoer niet uniek is, maar afhankelijk is van een experimentele controleparameter, wat cruciaal is voor metrologische toepassingen."
Het doel van de numerieke experimenten was om een aantal sterk verstrengelde kwantumtoestanden te ontruisen die onderhevig zijn aan spin-flip-fouten en willekeurige unitaire ruis. Hun algoritmen behaalden opmerkelijke resultaten en konden ook worden geïmplementeerd op huidige kwantumapparaten.
De algoritmen vereisen een kwantumcomputer die de specifieke experimentele output kan verwerken (d.w.z. kwantumgegevens). Bijvoorbeeld, als een onderzoeker de auto-encoders probeert te gebruiken om gegevens te denoise op basis van ingesloten ionen, maar haar kwantumcomputer gebruikt supergeleidende qubits, ze zal ook een techniek moeten gebruiken die toestanden van het ene fysieke platform naar het andere kan toewijzen.
"Het effectief trainen van onze auto-encoders vereist verschillende proeven, een aanzienlijke hoeveelheid experimentele gegevens, en het vermogen om de overeenkomst tussen kwantumtoestanden te meten, "Zeiden Bondarenko en Feldmann. "Niettemin, ons algoritme is niet al te verspillend met betrekking tot deze bronnen en onze voorbeelden zijn klein genoeg om gemakkelijk in te passen, tenminste in termen van het aantal qubits, in veel bestaande kwantumcomputers."
Hoewel is gebleken dat technieken voor het leren van kwantummachine en kwantumcomputers goed presteren in een verscheidenheid aan taken, onderzoekers proberen nog steeds de praktische toepassingen te identificeren waarvoor ze het meest nuttig kunnen zijn. De recente studie van Bondarenko en Feldmann biedt een duidelijk voorbeeld van hoe kwantummachine learning-methoden uiteindelijk kunnen worden gebruikt in praktijkscenario's.
"Het was helemaal niet duidelijk dat onze aanpak zou werken; en het doet meer dan alleen werken, althans in onze kleine voorbeelden, het werkt buitengewoon goed, ' zeiden Bondarenko en Feldmann.
In de toekomst, de door deze twee onderzoekers ontwikkelde kwantum-autoencoders kunnen worden gebruikt om de betrouwbaarheid van metingen die zijn verzameld met behulp van kwantumverbeterde tools te verbeteren, vooral degenen die verstrengelde toestanden met veel lichamen gebruiken. In aanvulling, ze zouden kunnen dienen als interfaces tussen verschillende kwantumarchitecturen.
"Verschillende kwantumapparaten hebben verschillende verdiensten, " zeiden Bondarenko en Feldmann. "Bijvoorbeeld, het is misschien makkelijker om koude atomen te gebruiken om de zwaartekracht te meten, fotonen zijn geweldig voor communicatie en supergeleidende qubits zijn nuttiger voor de verwerking van kwantuminformatie. Om informatie die tussen deze verschillende platforms wordt uitgewisseld om te zetten, hebben we interfaces nodig, die, zelf, fouten introduceren. Onze autoencoders kunnen helpen om deze uitgewisselde gegevens ongedaan te maken."
Bondarenko en Feldmann proberen nu een ander soort kwantumalgoritme te ontwikkelen:een terugkerend kwantumneuraal netwerk. De terugkerende architectuur van dit nieuwe algoritme zou het in staat moeten stellen informatie op te slaan die het in het verleden heeft verwerkt en een 'geheugen, " waarmee de onderzoekers kunnen corrigeren voor afwijkingen.
"Dit kan de kwantumexperimenten eenvoudiger maken omdat drifts worden weggefilterd door nabewerking, "Zeggen Bondarenko en Feldmann. "Een andere toepassing van terugkerende neurale netwerken is de ruisonderdrukking in het geval van langzaam veranderende ruis. Bijvoorbeeld, als men verstrengelde fotonen door de lucht stuurt, geluid kan verschillen tussen een besneeuwde bewolkte dag en een warme dag. Echter, het weer kan niet onmiddellijk veranderen, dus een algoritme met geheugen kan beter presteren dan een zonder."
© 2020 Wetenschap X Netwerk
 Belang van reptielen in het ecosysteem
Belang van reptielen in het ecosysteem- Beveiligingen die zijn ingesteld om de opwarming van de aarde te compenseren, zijn effectief om de panda-populaties sterk te houden
- Grondwaterstroming is de sleutel voor het modelleren van de wereldwijde watercyclus
- Verbruikt u wekelijks een creditcard ter waarde van plastic?
- Het verhaal van klimaatverandering en de Maya's verkeerd lezen
Hoofdlijnen
- Giftige Death Cap-paddenstoel verspreidt zich over Noord-Amerika
- Factoren die celdeling beïnvloeden
- 5 manieren om optimistisch te blijven in een neergaande economie
- Voeding door mensen verandert het gedrag en de fysiologie van groene schildpadden op de Canarische Eilanden
- Revolutionaire beeldvormingstechniek maakt gebruik van CRISPR om DNA-mutaties in kaart te brengen
- Wetenschappers ontcijferen het genoom van herfstlegerworm, mottenplaag die Afrika binnendringt
- Wat gebeurt er met de nucleaire envelop tijdens cytokinese?
Cytokinese is de verdeling van één cel in twee en is de laatste stap na de mitotische celcyclus in vier stadia. Tijdens cytokinese blijft de nucleaire envelop, of kernmembraan, die het gen
- Een plantencel maken uit gerecycleerde materialen
- Woestijnsprinkhanen - nieuwe risico's in het licht van klimaatverandering
- Onderzoekers vinden een betere machtswet die aardbevingen voorspelt, aderen, bankrekeningen
- Natuurkundigen ontwikkelen concept van nieuw snel niet-vluchtig geheugen

- Wetenschappers ontwikkelen een nieuwe tool voor het meten van radiogolven in fusieplasma's

- Het toepassen van afwisselende wendingen op een cilindrische container die ervoor zorgt dat de dobbelstenen op één lijn komen te liggen

- Natuurkundigen onthullen verband tussen twee niet-perturbatieve parameters om de productie van zware mesonen te helpen voorspellen


 Definitie van Concave Mirror
Definitie van Concave Mirror- Holografische microscoop biedt een nieuw hulpmiddel voor nanogeneeskunde om snel de afbraak van met medicijnen beladen nanodeeltjes te meten
- Unieke manieren om een DNA-model te bouwen
- Amerikaanse autoriteiten pakken StarKist op in ingeblikt tonijnschandaal
- Human Heart Science Projects
- Afbeelding:Robot ontmoet zijn meesters
- We beginnen het mysterie te ontrafelen van hoe bliksem en onweer werken
- Nieuwe supernova-analyse herkadert debat over donkere energie
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
