Wetenschap
Supercomputer analyseert webverkeer over het hele internet
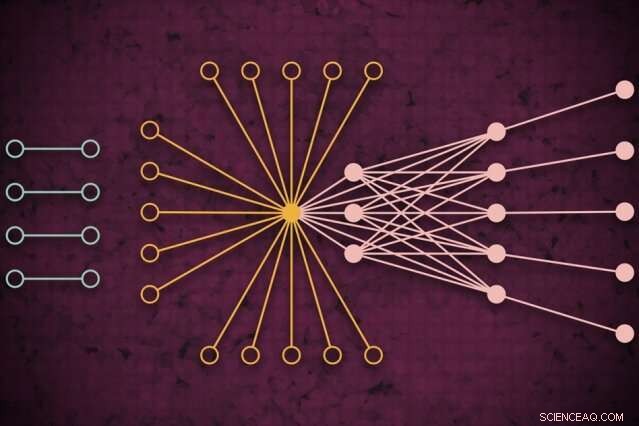
Met behulp van een supercomputersysteem, MIT-onderzoekers ontwikkelden een model dat vastlegt hoe het wereldwijde webverkeer er op een bepaalde dag uit zou kunnen zien, inclusief voorheen ongeziene geïsoleerde links (links) die zelden verbinding maken maar invloed lijken te hebben op het kernwebverkeer (rechts). Krediet:MIT Nieuws
Met behulp van een supercomputersysteem, MIT-onderzoekers hebben een model ontwikkeld dat vastlegt hoe internetverkeer er op een bepaalde dag over de hele wereld uitziet, die kan worden gebruikt als meetinstrument voor internetonderzoek en vele andere toepassingen.
Webverkeerspatronen op zo'n grote schaal begrijpen, zeggen de onderzoekers, is handig voor het informeren van internetbeleid, storingen opsporen en voorkomen, verdedigen tegen cyberaanvallen, en het ontwerpen van een efficiëntere computerinfrastructuur. Op de recente IEEE High Performance Extreme Computing Conference werd een paper gepresenteerd waarin de aanpak wordt beschreven.
Voor hun werk, de onderzoekers verzamelden de grootste publiek beschikbare dataset over internetverkeer, bestaande uit 50 miljard datapakketten die over een periode van meerdere jaren op verschillende locaties over de hele wereld zijn uitgewisseld.
Ze voerden de gegevens door een nieuwe "neurale netwerk"-pijplijn die over 10, 000 processors van de MIT SuperCloud, een systeem dat computerbronnen van het MIT Lincoln Laboratory en het hele instituut combineert. Die pijplijn heeft automatisch een model getraind dat de relatie voor alle links in de dataset vastlegt - van gewone pings tot reuzen zoals Google en Facebook, naar zeldzame links die slechts kort verbinding maken maar toch enige invloed lijken te hebben op het webverkeer.
Het model kan elke enorme netwerkdataset aan en een aantal statistische metingen genereren over hoe alle verbindingen in het netwerk elkaar beïnvloeden. Dat kan worden gebruikt om inzichten te onthullen over peer-to-peer bestandsdeling, snode IP-adressen en spamgedrag, de verspreiding van aanvallen in kritieke sectoren, en verkeersknelpunten om computerresources beter toe te wijzen en gegevens te laten stromen.
in concept, het werk is vergelijkbaar met het meten van de kosmische microgolfachtergrond van de ruimte, de bijna uniforme radiogolven die door ons universum reizen en een belangrijke informatiebron zijn geweest om verschijnselen in de ruimte te bestuderen. "We hebben een nauwkeurig model gebouwd om de achtergrond van het virtuele universum van internet te meten, " zegt Jeremy Kepner, een onderzoeker aan het MIT Lincoln Laboratory Supercomputing Center en een astronoom van opleiding. "Als je een variantie of anomalieën wilt detecteren, je moet een goed model van de achtergrond hebben."
Bij Kepner op het papier staan:Kenjiro Cho van het Internet Initiative Japan; KC Claffy van het Center for Applied Internet Data Analysis aan de Universiteit van Californië in San Diego; Vijay Gadepally en Peter Michaleas van het Supercomputing Center van Lincoln Laboratory; en Lauren Milechin, een onderzoeker bij MIT's Department of Earth, Atmosferische en planetaire wetenschappen.
Gegevens opsplitsen
Bij internetonderzoek experts bestuderen anomalieën in het webverkeer die erop kunnen wijzen, bijvoorbeeld, cyberdreigingen. Om dit te doen, het helpt om eerst te begrijpen hoe normaal verkeer eruit ziet. Maar dat vastleggen bleef een uitdaging. Traditionele "verkeersanalyse"-modellen kunnen alleen kleine steekproeven van datapakketten analyseren die worden uitgewisseld tussen bronnen en bestemmingen, beperkt door de locatie. Dat vermindert de nauwkeurigheid van het model.
De onderzoekers waren niet specifiek op zoek naar een oplossing voor dit verkeersanalyseprobleem. Maar ze hadden nieuwe technieken ontwikkeld die op de MIT SuperCloud konden worden gebruikt om enorme netwerkmatrices te verwerken. Internetverkeer was de perfecte testcase.
Netwerken worden meestal bestudeerd in de vorm van grafieken, met acteurs vertegenwoordigd door knooppunten, en links die verbindingen tussen de knooppunten vertegenwoordigen. Met internetverkeer, de knooppunten variëren in grootte en locatie. Grote supernodes zijn populaire hubs, zoals Google of Facebook. Bladknooppunten verspreiden zich vanaf die supernode en hebben meerdere verbindingen met elkaar en de supernode. Buiten die "kern" van supernodes en leaf-nodes bevinden zich geïsoleerde nodes en links, die slechts zelden met elkaar in verbinding staan.
Het vastleggen van de volledige omvang van die grafieken is onhaalbaar voor traditionele modellen. "Je kunt die gegevens niet aanraken zonder toegang tot een supercomputer, ' zegt Kepner.
In samenwerking met het Widely Integrated Distributed Environment (WIDE)-project, opgericht door verschillende Japanse universiteiten, en het Centrum voor Toegepaste Internet Data-analyse (CAIDA), in Californië, de MIT-onderzoekers hebben 's werelds grootste packet-capture dataset voor internetverkeer vastgelegd. De geanonimiseerde dataset bevat bijna 50 miljard unieke bron- en bestemmingsdatapunten tussen consumenten en verschillende apps en services op willekeurige dagen op verschillende locaties in Japan en de VS, daterend uit 2015.
Voordat ze een model op die gegevens konden trainen, ze moesten een uitgebreide voorbewerking doen. Om dit te doen, ze gebruikten software die ze eerder hadden gemaakt, genaamd Dynamic Distributed Dimensional Data Mode (D4M), die enkele middelingstechnieken gebruikt om "hypersparse gegevens" die veel meer lege ruimte bevatten dan gegevenspunten, efficiënt te berekenen en te sorteren. De onderzoekers braken de gegevens op in eenheden van ongeveer 100, 000 pakketten over 10, 000 MIT SuperCloud-processors. Dit genereerde compactere matrices van miljarden rijen en kolommen van interacties tussen bronnen en bestemmingen.
Uitbijters vastleggen
Maar de overgrote meerderheid van de cellen in deze hypersparse dataset was nog steeds leeg. Om de matrices te verwerken, het team had een neuraal netwerk op dezelfde 10, 000 kernen. Achter de schermen, een trial-and-error-techniek begon modellen aan te passen aan het geheel van de gegevens, het creëren van een kansverdeling van potentieel nauwkeurige modellen.
Vervolgens, het gebruikte een aangepaste foutcorrectietechniek om de parameters van elk model verder te verfijnen om zoveel mogelijk gegevens vast te leggen. traditioneel, foutcorrigerende technieken in machine learning zullen proberen de significantie van externe gegevens te verminderen om het model in een normale kansverdeling te laten passen, wat het over het algemeen nauwkeuriger maakt. Maar de onderzoekers gebruikten enkele wiskundige trucs om ervoor te zorgen dat het model nog steeds alle afgelegen gegevens - zoals geïsoleerde links - als significant voor de algehele metingen beschouwde.
Uiteindelijk, het neurale netwerk genereert in wezen een eenvoudig model, met slechts twee parameters, die de dataset internetverkeer beschrijft, "van echt populaire knooppunten tot geïsoleerde knooppunten, en het complete spectrum van alles daartussenin, ' zegt Kepner.
De onderzoekers zoeken nu contact met de wetenschappelijke gemeenschap om hun volgende toepassing voor het model te vinden. Experts, bijvoorbeeld, zou de betekenis kunnen onderzoeken van de geïsoleerde links die de onderzoekers in hun experimenten vonden, die zeldzaam zijn maar van invloed lijken te zijn op het webverkeer in de kernknooppunten.
Buiten het internet, de neurale netwerkpijplijn kan worden gebruikt om elk hypersparse netwerk te analyseren, zoals biologische en sociale netwerken. "We hebben de wetenschappelijke gemeenschap nu een fantastisch hulpmiddel gegeven voor mensen die robuustere netwerken willen bouwen of anomalieën van netwerken willen detecteren, " zegt Kepner. "Die afwijkingen kunnen gewoon normaal gedrag zijn van wat gebruikers doen, of het kunnen mensen zijn die dingen doen die je niet wilt."
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.
 Wat gebeurt er wanneer waterstof en zuurstof combineren?
Wat gebeurt er wanneer waterstof en zuurstof combineren? - Katalysatoren voor klimaatbescherming
- Elektrisch verwarmd textiel nu mogelijk
- Kan een veelgebruikt ingrediënt in wasmiddel helpen bij het bevorderen van diabetesonderzoek?
- Hydrogel 3D-print- en patroonvloeistoffen met het condensatorrandeffect (PLEEC)
- Wat zijn de vijf biotische factoren van een aquatisch ecosysteem?
- Kustmist gekoppeld aan hoge niveaus van kwik gevonden in bergleeuwen, studie vondsten
- Onderzoek toont aan dat ongewone microben aanwijzingen bevatten voor het vroege leven
- Dodental van tyfoon Filipijnen bereikt 50
- Samenwerking leidt tot meer vertrouwen in agrarisch natuurbeheer
Hoofdlijnen
- Meer dan een getallenspel:nieuwe techniek meet microbiële gemeenschappen op biomassa
- Computerprogramma detecteert verschillen tussen menselijke cellen
- De relatie tussen leeftijd en plasticiteit
- Wat kan je spit je vertellen over je DNA?
- Kleine wespenlichamen betekent kleine hersengebieden van wespen, studie toont
- Verrassend onderzoek bij apen vindt dat slechte tijden er niet toe leiden dat groepsleden hun gedrag veranderen
- Gegevensmodellering is de sleutel tot duurzaam visserijbeheer
- Nieuwe studie laat zien hoe mierenkolonies zich anders gedragen in verschillende omgevingen
- Ezels hebben meer bescherming nodig tegen de winter dan paarden
- Brainwave-apparaten kunnen gevoelige medische aandoeningen en persoonlijke informatie lekken

- Systeem traint auto's zonder bestuurder in simulatie voordat ze de weg op gaan

- Virtuele modellen van het menselijk lichaam vormen een aanvulling op crashtestdummies
- Met een miljard gebruikers, Instagram neemt YouTube op in video (update)

- Nieuwe technologieën in de oceaanenergiesector


 Boeing nam geen belangrijke waarborgen op 737 MAX op:rapport
Boeing nam geen belangrijke waarborgen op 737 MAX op:rapport- Op klei gebaseerde antimicrobiële verpakking houdt voedsel vers
- Hoe de lineaire beelden van een cirkel te berekenen
- Waarom wordt de Calvin-cyclus beschouwd als een donkere reactie?
- Goed bewaarde wolharige neushoorn uit de ijstijd gevonden in Siberië
- Veel vis in de zee? Niet noodzakelijk, zoals de geschiedenis laat zien
- Hoe te berekenen Volume
- Kankercellen targeten door elektrische stromen te meten
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | German | Dutch | Danish | Swedish | Norway |

-
Wetenschap © https://nl.scienceaq.com
