Wetenschap
Onderzoekers ontwikkelen een nieuw systeem om misbruik in online communities op te sporen
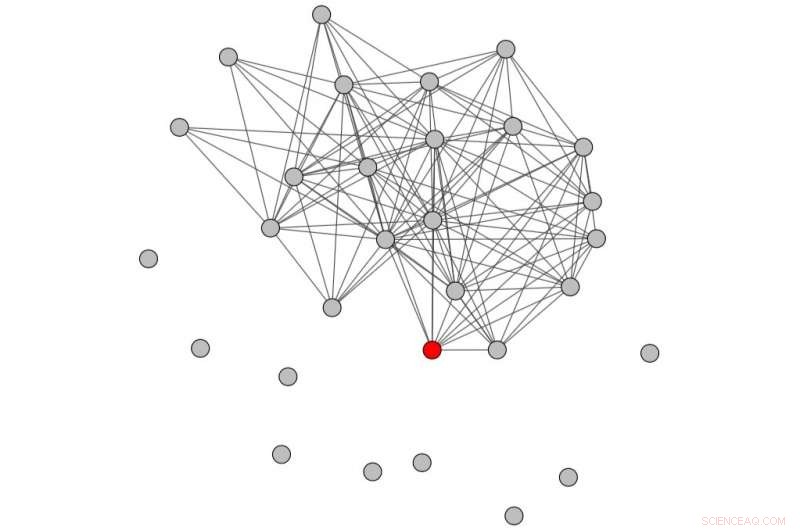
Conversatiegrafiek verkregen door te kijken naar een periode voorafgaand aan het misbruik. Krediet:Papegnies et al.
Een team van onderzoekers van de Universiteit van Avignon heeft onlangs een systeem ontwikkeld om misbruik in online communities automatisch te detecteren. Dit systeem, gepresenteerd in een paper dat vooraf is gepubliceerd op arXiv, bleek beter te presteren dan bestaande benaderingen voor het opsporen van misbruik en het modereren van door gebruikers gegenereerde inhoud.
"Steeds groeiende online communities bieden de mogelijkheid om ideeën via internet te verspreiden, het garanderen van enige anonimiteit aan gebruikers, " vertelden de onderzoekers aan TechXplore, via e-mail. "Echter, deze ruimtes hebben vaak gebruikers die beledigend gedrag vertonen. Voor gemeenschapsleiders, het is belangrijk om deze kwaadaardige handelingen te modereren, omdat het nalaten hiervan de gemeenschap zou kunnen vergiftigen, gebruikers exodus te activeren en beheerders bloot te stellen aan juridische problemen."
Het modereren van online door gebruikers gegenereerde inhoud wordt over het algemeen handmatig door mensen uitgevoerd; Vandaar, het kan zowel duur als tijdrovend zijn. Om de kosten te verlagen, onderzoekers hebben geprobeerd om volledig geautomatiseerde tools voor contentmoderatie te ontwikkelen die menselijke moderators kunnen vervangen of helpen.
"In dit werk, we formuleren de taak van contentmoderatie als een classificatieprobleem, en onze methode toepassen op een corpus van berichten uitgewisseld door spelers van een MMORPG, een massaal multiplayer online rollenspel, ', aldus de onderzoekers.
Als eerste stap, de onderzoekers haalden gespreksnetwerken uit onbewerkte chatlogboeken die de gesprekken vertegenwoordigen waarin elk beledigend bericht werd verzonden, en gekarakteriseerd ze met behulp van topologische maatregelen. Ze gebruikten hun resultaten als kenmerken, het trainen van een classifier om misbruik op online platforms op te sporen.
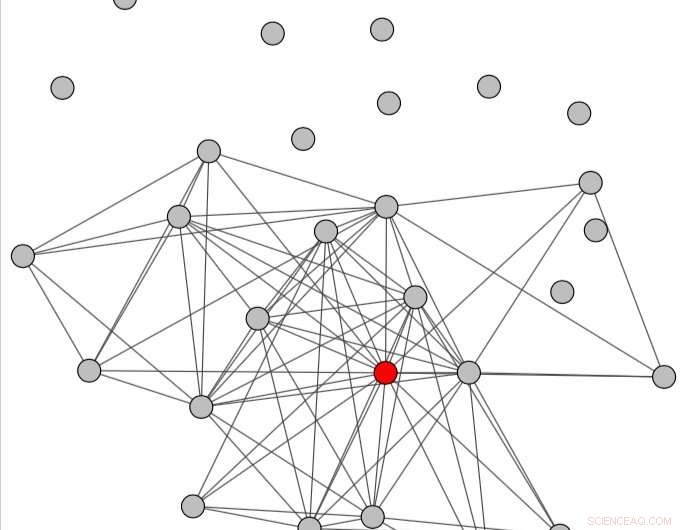
De gespreksgrafiek verkregen door een periode na het misbruik te beschouwen. Krediet:Papegnies et al.
Bij het extraheren van de gespreksnetwerken, de onderzoekers volgden een driestappenmethode. Eerst, ze identificeerden de subset van berichten die ze zouden gebruiken om het netwerk te extraheren. Vervolgens, ze selecteerden een subset van gebruikers die de waarschijnlijke ontvangers van elk bericht waren. Eindelijk, ze voegden randen toe en herzien hun gewichten op basis van deze potentiële berichtontvangers.
"Bestaande methoden voor de automatische detectie van beledigende berichten richten zich op de tekstuele inhoud van de uitgewisselde berichten, die veel problemen oproept:taalspecifieke problemen, syntaxis fouten, spelfouten, verduistering, en anderen, " legden de onderzoekers uit. "Integendeel, we gebruiken alleen de aanwezigheid/afwezigheid van interacties tussen gebruikers, d.w.z. het feit dat ze sommige berichten uitwisselen (of niet), door verzet tegen de aard van de uitgewisselde berichten. Door de inhoud te negeren, konden we deze problemen oplossen."
Eigenlijk, de onderzoekers modelleerden online conversaties met behulp van een grafiek waarin knooppunten gebruikers vertegenwoordigen en links berichtenuitwisselingen vertegenwoordigen. Met behulp van grafiek-specifieke maatregelen, ze konden verschillen waarnemen in de manier waarop gesprekken zijn gestructureerd, afhankelijk van het feit of ze al dan niet beledigende berichten bevatten. Deze verschillen werden vervolgens gebruikt om een classifier te trainen om misbruik in gesprekken tussen gebruikers te detecteren.
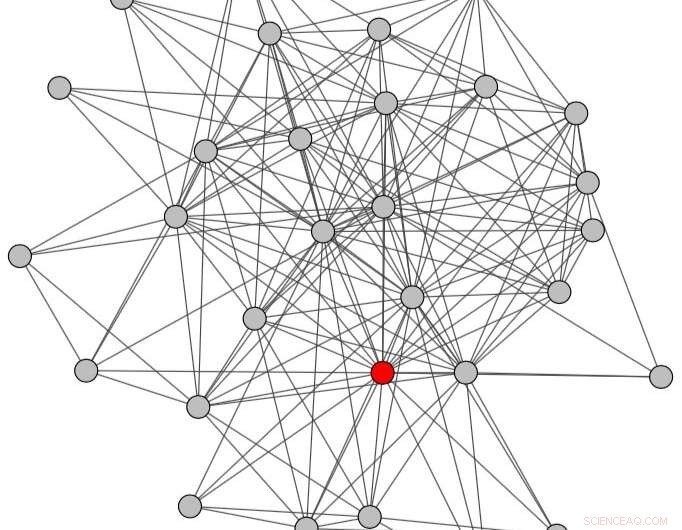
Conversatiegrafiek verkregen door de hele tijdsperiode te beschouwen (d.w.z. zowel voor als na het misbruik). Krediet:Papegnies et al.
"Onze eerste poging, gepresenteerd in een vorig artikel, was gebaseerd op de traditionele benadering, d.w.z., het gebruikte de tekstuele inhoud van berichten, " legden de onderzoekers uit. "Toen we deze op grafieken gebaseerde methode voorstelden, we hadden niet verwacht dat het zo goed zou werken; we dachten zelfs dat het zou resulteren in lagere prestaties in vergelijking met de content-based methode. We waren zeer verrast om aanzienlijk betere resultaten te behalen. Dit is de meest betekenisvolle bevinding van onze studie - dat, althans voor deze specifieke taak, de structuur van het gesprek is meer onderscheidend dan de aard van de uitgewisselde inhoud."
-
Krediet:Papegnies et al.
-
Krediet:Papegnies et al.
De onderzoekers testten hun systeem op een dataset van gebruikerscommentaar van een Frans MMORPG-spel en ontdekten dat het beter presteerde dan bestaande benaderingen. met een F-maat van 83,89 bij gebruik van de volledige functieset. Door de functieset te verminderen en alleen de meest onderscheidende kenmerken te behouden, ze waren in staat om de rekentijd drastisch te verminderen, met behoud van uitstekende prestaties. In de toekomst, hun op grafieken gebaseerde benadering zou ook kunnen worden toegepast op andere berichtenclassificatietaken, zoals online trolldetectie.
"We zullen nu proberen beide benaderingen (inhouds- en grafiekgebaseerd) samen te voegen, om te controleren of zij gebruik maken van soortgelijke informatie, in dat geval zouden de resultaten vergelijkbaar zijn, of als ze vertrouwen op aanvullende informatie, in welk geval, het combineren ervan zou moeten leiden tot prestatieverbeteringen, " voegden de onderzoekers eraan toe. "Vervolgens, we willen evolueren naar een meer geautomatiseerde methode om onze gespreksgrafieken te karakteriseren, grafiekinbeddingen genoemd. Het is een op deep learning gebaseerde methode die bestaat uit het trainen van een neuraal netwerk om een efficiënte weergave van de grafieken te krijgen. Ter vergelijking, we doen dit deel van het werk momenteel handmatig, via een taak genaamd functieselectie."
© 2019 Wetenschap X Netwerk
 De staat Washington experimenteert met buyouts, uiterwaarden herstellen om toekomstige rampen te voorkomen
De staat Washington experimenteert met buyouts, uiterwaarden herstellen om toekomstige rampen te voorkomen- Nieuw model suggereert verloren continenten voor de vroege aarde
- Onderzoekers onderzoeken de diepe biosfeer van de oceanen
- Vraag en antwoord:Hoe het mensenrecht op een gezonde omgeving ons allemaal kan helpen beschermen
- Nul herstel voor koralen bij back-to-back bleking in Australië
Hoofdlijnen
- Hoe een onbekende bacterie in de microbiologie te identificeren
- Slimme app gebruikt smartphonecamera om plantensoorten te identificeren
- Zes belangrijkste celfuncties
- Wat is de meest logische volgorde van stappen voor het splitsen van vreemd DNA?
- Getrainde haviken schrikken kleinere vogels af, trek blikken in LA
- Mieren offeren hun koloniegenoten op als onderdeel van een dodelijke desinfectie
- Virussen bestrijden:codebrekers worden codeschrijvers
- Hoe bouw je een DNA-model uit tandenstokers
- Bedoelden ze dat? Ongeval en opzet in een octopussentuin
- Miljardair Bezos koopt landgoed voor $ 165 miljoen:rapport

- Spotify waarschuwt voor tragere verkoopgroei naarmate de beursgang in New York nadert

- Circulaire economie kan de winstgevendheid van windenergie verbeteren - en vice versa

- Op garnalen geïnspireerde camera kan onderwaternavigatie mogelijk maken

- Groeiende plutoniumvoorraad in Japan voedt angsten


 Amazon trekt stekker uit Chinese retailactiviteiten:rapport
Amazon trekt stekker uit Chinese retailactiviteiten:rapport- Onderzoekers publiceren een gedetailleerd beeld van de stroom van biologische deeltjes in de diepzee langs de evenaar
- Toegankelijke gezondheidszorg kan de sleutel zijn tot het oplossen van de klimaatcrisis
- Wat doet een massaspectrometer?
- Atomtronic-apparaat zou de grens kunnen onderzoeken tussen kwantum, alledaagse werelden
- Berekening van verlopen op een topografische kaart
- Wat is het verschil tussen TIG-lassen en MIG-lassen?
- Basiscomponenten van Math
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
