Wetenschap
Wide learning AI-technologie maakt zeer nauwkeurig leren mogelijk, zelfs van onevenwichtige datasets
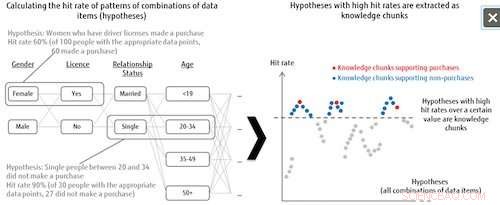
Figuur 1:Hypotheselijst en kennisbrokextractie. Krediet:Fujitsu
Fujitsu Laboratories Ltd. heeft vandaag de ontwikkeling aangekondigd van "Wide Learning, " een machine learning-technologie die in staat is tot nauwkeurige beoordelingen, zelfs wanneer operators niet de hoeveelheid gegevens kunnen verkrijgen die nodig zijn voor training. AI wordt nu vaak gebruikt om gegevens op verschillende gebieden te benutten, maar de nauwkeurigheid van AI kan worden beïnvloed in gevallen waarin de hoeveelheid te analyseren gegevens klein of onevenwichtig is. Fujitsu's Wide Learning-technologie maakt het mogelijk om nauwkeuriger te oordelen dan voorheen mogelijk was, en het leren wordt uniform bereikt, ongeacht welke hypothese wordt onderzocht, zelfs wanneer de gegevens onevenwichtig zijn. Het bereikt dit door eerst hypothesen te extraheren met een hoge mate van belang, een groot aantal hypothesen hebben gemaakt die zijn gevormd door alle combinaties van gegevensitems, en vervolgens door te controleren voor de mate van impact van elke respectievelijke hypothese op basis van de overlappende relaties van de hypothesen. Bovendien, omdat de hypothesen worden vastgelegd als logische uitdrukkingen, mensen kunnen ook de redenering achter een oordeel begrijpen. Fujitsu's nieuwe Wide Learning-technologie maakt het gebruik van AI mogelijk, zelfs op gebieden zoals gezondheidszorg en marketing, waar de gegevens die nodig zijn om een oordeel te vellen schaars zijn, het ondersteunen van operaties en het bevorderen van de automatisering van werkprocessen met behulp van AI.
In recente jaren, AI-technologie wordt op verschillende gebieden gebruikt, inclusief gezondheidszorg, marketing, en financiën. Er worden steeds meer verwachtingen gewekt voor het gebruik van AI-besluitvorming ter ondersteuning van operaties en het automatiseren van taken op deze gebieden. Een uitdaging die overblijft om het potentieel van deze technologieën te realiseren, echter, is dat de gegevens onevenwichtig kunnen zijn. specifiek, afhankelijk van de branche kan het moeilijk zijn om voldoende gegevens te verkrijgen voor het trainen van AI over de doelen waarover het moet oordelen. Dit, in werkelijkheid, laat veel van deze technologieën niet in staat om resultaten te produceren met voldoende nauwkeurigheid voor praktisch gebruik. Verder, een belangrijke reden waarom de inzet van AI geen vooruitgang boekt, is dat zelfs wanneer een AI voldoende nauwkeurige herkennings- of classificatieprestaties biedt, experts en zelfs de ontwikkelaars zelf kunnen vaak niet verklaren waarom de AI een bepaald antwoord opleverde, en als ze hun verantwoordelijkheid niet kunnen nemen om de resultaten aan de frontlinies van de industrie uit te leggen, kan AI niet worden ingezet.
AI-technologieën gebaseerd op deep learning maken conventioneel zeer nauwkeurige beoordelingen door te worden getraind op grote hoeveelheden gegevens, inclusief voldoende doelgegevens om te beoordelen. In echte wereldscenario's, echter, er zijn veel gevallen waarin de gegevens onvoldoende zijn, met extreem weinig doelgegevens. In deze gevallen, wanneer ze worden geconfronteerd met onbekende gegevens, het wordt moeilijk voor AI-technologie om zeer nauwkeurige beoordelingen te geven. Bovendien, het machine learning-model voor bestaande AI op basis van deep learning is een black box-model dat de redenen achter de oordelen van de AI niet kan verklaren, een probleem met transparantie creëren. Als zodanig, in de toekomst zal het nodig zijn om nieuwe AI-technologie te ontwikkelen die zeer nauwkeurige beoordelingen realiseert op basis van onevenwichtige gegevens, en dat is ook transparant om verschillende maatschappelijke vraagstukken op te lossen.
Met deze uitdagingen in het achterhoofd, Fujitsu Laboratories heeft nu Wide Learning ontwikkeld, een machine learning-technologie die in staat is om zeer nauwkeurige beoordelingen te maken, zelfs in gevallen waarin de gegevens onevenwichtig zijn. De kenmerken van Wide Learning-technologie omvatten de volgende twee punten.
1. Creëert combinaties van gegevensitems om grote hoeveelheden hypothesen te extraheren
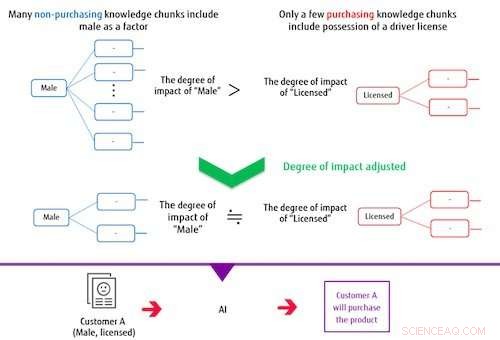
Figuur 2:Bij het maken van een classificatiemodel, de kennisbrokken hebben invloed op aanpassing. Krediet:Fujitsu
Deze technologie behandelt alle combinatiepatronen van gegevensitems als hypothesen, en bepaalt vervolgens de mate van belangrijkheid van elke hypothese op basis van het hitpercentage voor de labelcategorie. Bijvoorbeeld, bij het analyseren van trends in wie bepaalde producten koopt, het systeem combineert allerlei patronen uit de data-items voor degenen die wel of niet aankopen hebben gedaan (het categorielabel), zoals alleenstaande vrouwen tussen 20-34 jaar die een rijbewijs hebben, en analyseert vervolgens hoeveel hits het krijgt in de gegevens van degenen die daadwerkelijk aankopen hebben gedaan wanneer deze combinatiepatronen als hypothesen worden genomen. De hypothesen die een hitrate boven een bepaald niveau halen, worden gedefinieerd als belangrijke hypothesen, zogenaamde "kennisbrokken". Dit betekent dat zelfs wanneer de doelgegevens onvoldoende zijn, het systeem kan alle hypothesen extraheren die het onderzoeken waard zijn, die ook kunnen bijdragen aan het ontdekken van voorheen ondoordachte verklaringen.
2. Past de mate van impact van kennisbrokken aan om een nauwkeurig classificatiemodel te bouwen
Het systeem bouwt een classificatiemodel op basis van meerdere geëxtraheerde kennisbrokken en op het doellabel. In dit proces, als de items die deel uitmaken van een kennisbrok vaak overlappen met de items die deel uitmaken van andere kennisblokken, het systeem controleert hun mate van impact om het gewicht van hun invloed op het classificatiemodel te verminderen. Op deze manier, het systeem kan een model trainen dat in staat is tot nauwkeurige classificaties, zelfs wanneer het doellabel of de als correct gemarkeerde gegevens onevenwichtig zijn. Bijvoorbeeld, in een geval waarin mannen die geen aankoop hebben gedaan de overgrote meerderheid uitmaken van een aankoopdataset voor artikelen, als de AI wordt getraind zonder de mate van impact te beheersen, dan de kennisbrok die aangeeft of een persoon een licentie heeft of niet, onafhankelijk van geslacht, zal niet veel invloed hebben op de indeling. Met deze nieuw ontwikkelde methode de mate van impact van kennisbrokken inclusief man als factor is beperkt door de overlap van dit item, terwijl de impact van het kleinere aantal kennisbrokken, waaronder het al dan niet hebben van een licentie, relatief groter wordt in opleiding, het bouwen van een model dat zowel mannen als het bezit van een licentie correct kan categoriseren.
Fujitsu Laboratories heeft deze technologie getest, toepassen op data op gebieden als digitale marketing en gezondheidszorg. In een test met benchmarkgegevens op het gebied van marketing en gezondheidszorg uit de UC Irvine Machine Learning Repository, deze technologie verbeterde de nauwkeurigheid met ongeveer 10-20% in vergelijking met deep learning. Het verminderde met succes de kans dat het systeem klanten over het hoofd zou zien die zich op een dienst zouden abonneren of patiënten met een aandoening met ongeveer 20-50%. In de marketinggegevens van de ongeveer 5 000 klantgegevensinvoer gebruikt in de test, slechts ongeveer 230 waren voor kopende klanten, zorgen voor een onevenwichtige set. Deze technologie verminderde het aantal potentiële klanten dat werd uitgesloten van verkooppromoties van 120, het resultaat van diepgaande leeranalyse, tot 74. Bovendien omdat de kennisbrokken die de basis vormen voor deze technologie een logisch expressieformaat hebben, het vermogen om de redenering achter een oordeel uit te leggen is ook nuttig bij het implementeren van deze technologie in de samenleving. Zelfs wanneer wordt vastgesteld dat correcties aan een model nodig zijn, op basis van resultaten van nieuwe gegevens, het is mogelijk om meer geschikte revisies aan te brengen, omdat gebruikers de redenen voor resultaten kunnen begrijpen.
Fujitsu Laboratories zal deze technologie blijven toepassen op taken die de redenering achter AI-oordelen vereisen, zoals bij financiële transacties en medische diagnoses, en voor taken die omgaan met laagfrequente verschijnselen, zoals fraude en defecten aan apparatuur, met als doel het in fiscaal 2019 te commercialiseren als een nieuwe machine learning-technologie die Fujitsu Human Centric AI Zinrai van Fujitsu Limited ondersteunt. Fujitsu Laboratories zal ook effectief gebruik maken van het karakteristieke vermogen van deze technologie voor uitleg, voortzetting van onderzoek en ontwikkeling naar onderwerpen als verbeterde ondersteuning voor het maken van oordelen en beslissingen in taken waarop het wordt toegepast, en in het algehele systeemontwerp, inclusief samenwerking met mensen.
 Hoe de eerste ionisatie-energie van het waterstofatoom te berekenen met betrekking tot de Balmer-serie
Hoe de eerste ionisatie-energie van het waterstofatoom te berekenen met betrekking tot de Balmer-serie- Nanokristallijne materialen met verminderde zuurstof vertonen verbeterde prestaties
- Chemische katalysator verandert afval in schat, inerte C-H-bindingen reactief maken
- Hoe het chemische symbool voor Ions
- Unieke nieuwe antivirale behandeling gemaakt met suiker
Hoofdlijnen
- Wat is de meest logische volgorde van stappen voor het splitsen van vreemd DNA?
- Onderzoekers identificeren genen die zoogdieren van andere dieren onderscheiden
- Wat is de rol van ademhalingssystemen in homeostase?
- DNA is digitaal geworden - wat kan er mis gaan?
- Studie identificeert waarschijnlijke scenario's voor wereldwijde verspreiding van verwoestende gewasziekte
- "What Does Heterozygous Mean?
- Europarlementariërs dringen aan op onderzoek naar Monsantos heerschappij over veiligheidsstudies
- Wanneer citroenen je leven geven:Herpetofauna-aanpassing aan citrusboomgaarden in Belize
- Het grote structurele voordeel Eukaryoten hebben over prokaryoten
- Software beter in het aanpakken van IS-propaganda, Facebook zegt

- De transitie naar duurzame steden versnellen

- Koppelingen en uiteenvallen van autofabrikanten

- Geneesmiddelenfabrikant Pfizers CEO Read wordt vervangen door COO Bourla

- Gebrek aan Pools, ontbrekende inhoud mar AT&T's nieuwe snoersnijderservice


 Lange ruimtevluchten bleken in sommige gevallen te leiden tot bloedstroom in de verkeerde richting
Lange ruimtevluchten bleken in sommige gevallen te leiden tot bloedstroom in de verkeerde richting- In welke laag van de aardatmosfeer cirkelen kunstmatige satellieten om de aarde?
- Bloedvlekken detecteren - met een antimalariamiddel
- Laboratoriumexperimenten die het mysterie van de Marsmaan Phobos . ontrafelen
- Gigantische lavakoepel bevestigd in de Japanse Kikai Caldera
- Lopende robots, een YouTube-sensatie, maak je klaar voor de markt
- Op weg naar robuuste microgolfopwekking op nanoschaal
- De temperatuur van de oceaan meten door de snelheid te meten van de geluidsgolven die er doorheen gaan
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
