Wetenschap
Semantische cache voor AI-enabled beeldanalyse
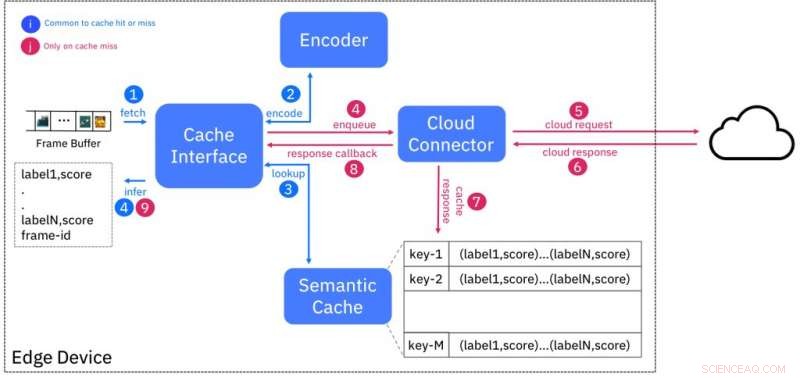
Blokdiagram van semantische cacheservice. Krediet:IBM
De beschikbaarheid van hoge resolutie, goedkope sensoren hebben de hoeveelheid geproduceerde gegevens exponentieel vergroot, die het bestaande internet zouden kunnen overweldigen. Dit heeft geleid tot de behoefte aan rekencapaciteit om de gegevens te verwerken in de buurt van waar ze worden gegenereerd, aan de randen van het netwerk, in plaats van het naar clouddatacenters te sturen. Edge-computing, zoals dit bekend is, vermindert niet alleen de druk op de bandbreedte, maar vermindert ook de latentie bij het verkrijgen van intelligentie uit onbewerkte gegevens. Echter, beschikbaarheid van resources aan de edge is beperkt vanwege het gebrek aan schaalvoordelen die de cloudinfrastructuur kosteneffectief maken om te beheren en aan te bieden.
Het potentieel van edge computing is nergens duidelijker dan bij video-analyse. High-definition (1080p) videocamera's worden gemeengoed in domeinen zoals bewaking en, afhankelijk van de framesnelheid en datacompressie, kan 4-12 megabits aan gegevens per seconde produceren. Nieuwere camera's met 4K-resolutie produceren onbewerkte gegevens in de orde van gigabits per seconde. De behoefte aan realtime inzichten in dergelijke videostreams stimuleert het gebruik van AI-technieken zoals diepe neurale netwerken voor taken zoals classificatie, objectdetectie en extractie, en anomaliedetectie.
In onze Hot Edge 2018 Conference Paper "Shadow Puppets:Cloud-level Accurate AI Inference at the Speed and Economy of Edge, " ons team bij IBM Research - Ierland heeft experimenteel de prestaties van een dergelijke AI-workload geëvalueerd, objectclassificatie, gebruik maken van in de handel verkrijgbare door de cloud gehoste services. Het beste resultaat dat we konden behalen was een classificatie-output van 2 frames per seconde, wat ver onder de standaard videoproductiesnelheid van 24 frames per seconde ligt. Het uitvoeren van een soortgelijk experiment op een representatief edge-apparaat (NVIDIA Jetson TK1) voldeed aan de latentievereisten, maar gebruikte tijdens dit proces de meeste beschikbare bronnen op het apparaat.
We doorbreken deze dualiteit door de Semantic Cache voor te stellen, een aanpak die de lage latentie van edge-implementaties combineert met de bijna oneindige resources die beschikbaar zijn in de cloud. We gebruiken de bekende techniek van caching om latentie te maskeren door AI-inferentie uit te voeren voor een bepaalde invoer (bijvoorbeeld videoframe) in de cloud en de resultaten op de rand op te slaan tegen een "vingerafdruk", of een hashcode, gebaseerd op kenmerken die uit de invoer zijn geëxtraheerd.
Dit schema is zo ontworpen dat ingangen die semantisch vergelijkbaar zijn (bijv. behorend tot dezelfde klasse) vingerafdrukken hebben die "dichtbij" bij elkaar liggen, volgens een afstandsmaat. Figuur 1 toont het ontwerp van de cache. De encoder maakt de vingerafdruk van een invoervideoframe en zoekt in de cache naar vingerafdrukken binnen een bepaalde afstand. Als er een match is, dan worden de inferentieresultaten geleverd vanuit de cache, waardoor de noodzaak wordt vermeden om de AI-service in de cloud te ondervragen.
We vinden de vingerafdrukken analoog aan schaduwpoppen, tweedimensionale projecties van figuren op een scherm gecreëerd door een licht op de achtergrond. Iedereen die zijn/haar vingers heeft gebruikt om schaduwpoppen te maken, zal beamen dat het ontbreken van details in deze figuren hun vermogen om de basis te vormen voor een goed verhaal niet beperkt. De vingerafdrukken zijn projecties van de daadwerkelijke invoer die kan worden gebruikt voor rijke AI-toepassingen, zelfs als er geen originele details zijn.
We hebben een complete proof of concept-implementatie van de semantische cache ontwikkeld, volgens een "as a service"-ontwerpbenadering, en het blootstellen van de service aan gebruikers van edge-apparaten/gateways via een REST-interface. Onze evaluaties op een reeks diverse edge-apparaten (Raspberry Pi 3/ NVIDIA Jetson TK1/TX1/TX2) hebben aangetoond dat de latentie van inferentie met 3 keer is verminderd en het bandbreedtegebruik met ten minste 50 procent in vergelijking met een cloud- enige oplossing.
Vroege evaluatie van een eerste prototype-implementatie van onze aanpak toont het potentieel ervan. We gaan door met het rijpen van de oorspronkelijke aanpak, prioriteit geven aan het experimenteren met alternatieve coderingstechnieken voor verbeterde precisie, terwijl de evaluatie ook wordt uitgebreid tot verdere datasets en AI-taken.
We voorzien deze technologie voor toepassingen in de detailhandel, voorspellend onderhoud voor industriële installaties, en videobewaking, onder andere. Bijvoorbeeld, de semantische cache kan worden gebruikt om vingerafdrukken van productafbeeldingen bij de kassa op te slaan. Dit kan worden gebruikt om winkelverliezen door diefstal of verkeerd scannen te voorkomen. Onze aanpak dient als een voorbeeld van naadloos schakelen tussen cloud- en edge-services om de beste AI-oplossingen aan de edge te leveren.
Dit verhaal is opnieuw gepubliceerd met dank aan IBM Research. Lees hier het originele verhaal.
 Tips voor het onthouden van sterke zuren en basen
Tips voor het onthouden van sterke zuren en basen - Synthese van het veterinaire antibioticum florfenicol via een snelle chemo-enzymatische route
- Voors en tegens van natuurlijke suiker en kunstmatige zoetstoffen
- Invoeging van boor in alkyletherbindingen via tandemkatalyse van zink/nikkel
- Kosteneffectieve methode produceert halfgeleidende films van materialen die beter presteren dan silicium
- 3D-geprinte modellen zorgen voor een beter begrip van grondbewegingen
- Klimaatverandering zal de blootstelling van de mens aan het giftige methylkwik waarschijnlijk verhogen
- Anatomie en fysiologie Projectideeën
- Zijn depressies in de Canadese prairies de sleutel tot het aanvullen van grondwater?
- Emissies keren terug naar pre-pandemische niveaus in het grootste olieveld van het land
Hoofdlijnen
- Wat gebeurt er in de interfase van de celcyclus?
- Welke vier dingen maken ribosomen anders dan organellen?
- Zoogdieren schakelden over op dagactiviteit na uitsterven van dinosauriërs
- Wat doet acetonalcohol met een gramkleuring?
- Video:Op weg naar nul honger wereldwijd
- Ontmoet Afrika's vogelmeester van vocale imitatie
- DNA-modellen maken met behulp van papier
- Het verschil tussen hoe interne en externe regulatoren werken
- Namen van de structurele componenten van het menselijk hart
- Zelfrijdende shuttles:waar wachten we nog op?

- G7-landen zijn het eens over een gemeenschappelijke visie voor AI

- Boeing zou productie op 787-vliegtuig opnieuw kunnen verlagen:bron

- Vierdimensionale microbouwstenen:afdrukbaar, tijd gerelateerd, programmeerbare tools
- Hypothetisch menselijk exoskelet met veermechanisme zou de loopsnelheid kunnen verdubbelen


 De bouw van de metro in Rome onthult een militair huis uit de 2e eeuw
De bouw van de metro in Rome onthult een militair huis uit de 2e eeuw- 14-jarige FaceTime-bug-ontdekking zou Apple kunnen rammelen
- Conclusies opstellen voor wetenschapsprojecten
- Een nieuwe kijk op de bronnen en effecten van broeikasgassen in China
- Hoe kan een streepjescode uw leven redden?
- Uitgestorven dieren in het Amazone-regenwoud
- Hoe Fog-Machine Fluid
- Nieuw algoritme vindt het optimale breekpunt voor bindingen voor afzonderlijke moleculen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
