Wetenschap
Semantische concepten ontdekken via gebeurtenisdatabases

Vergelijking van concept rankings voor een Human Rights Watch Report. De kolom 'Grondwaarheid' toont de acht meest genoemde personen in het rapport 'Venezuela's humanitaire crisis', terwijl de andere kolommen waarden tonen die zijn geretourneerd door verschillende detectiemethoden. Waarden die tot de grondwaarheidsconcepten behoren, worden aangegeven met donkere hokjes. De contextmethode retourneert waarden die allemaal relevant zijn (zelfs als ze ontbreken in het oorspronkelijke artikel), overwegende dat de methode van gelijktijdig voorkomen veel populaire maar irrelevante concepten oplevert (bijv. politici die algemene uitspraken over het onderwerp doen). Krediet:IBM
Bij IBM Research AI, we hebben een op AI gebaseerde oplossing gebouwd om analisten te helpen bij het opstellen van rapporten. De paper die dit werk beschrijft, won onlangs de prijs voor beste paper op de "In-Use" Track van de 2018 Extended Semantic Web Conference (ESWC).
Analisten zijn vaak belast met het opstellen van uitgebreide en nauwkeurige rapporten over bepaalde onderwerpen of vragen op hoog niveau, die door organisaties kunnen worden gebruikt, ondernemingen, of overheidsinstanties om weloverwogen beslissingen te nemen, het verminderen van het risico verbonden aan hun toekomstplannen. Om dergelijke rapporten op te stellen, analisten moeten onderwerpen identificeren, mensen, organisaties, en gebeurtenissen die verband houden met de vragen. Als voorbeeld, om een rapport op te stellen over de gevolgen van de Brexit voor de Londense financiële markten, een analist moet op de hoogte zijn van de belangrijkste gerelateerde onderwerpen (bijv. financiële markten, economie, brexit, brexit-echtscheidingswet), mensen en organisaties (bijv. De Europese Unie, besluitvormers in de EU en het VK, mensen die betrokken zijn bij de brexitonderhandelingen), en evenementen (bijv. Onderhandelingsbijeenkomsten, Parlementsverkiezingen binnen de EU, enzovoort.). Een AI-ondersteunde oplossing kan analisten helpen om volledige rapporten op te stellen en ook vooroordelen op basis van ervaringen uit het verleden te voorkomen. Bijvoorbeeld, een analist zou een belangrijke informatiebron kunnen missen als deze in het verleden niet effectief is gebruikt.
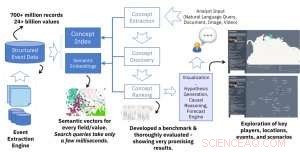
Het kennisinductieteam van IBM Research AI heeft de oplossing gebouwd met behulp van deep learning en gestructureerde gebeurtenisgegevens. Het team, onder leiding van Alfio Gliozzo, won vorig jaar ook de prestigieuze Semantic Web Challenge-prijs.
Semantische inbeddingen uit gebeurtenisdatabases
De belangrijkste technische nieuwigheid van dit werk is het creëren van semantische inbeddingen uit gestructureerde gebeurtenisgegevens. De invoer voor onze semantische inbeddingsengine is een grote gestructureerde gegevensbron (bijv. databasetabellen met miljoenen rijen) en de uitvoer is een grote verzameling vectoren met een constante grootte (bijv. 300) waarbij elke vector de semantische context van een waarde in de gestructureerde gegevens vertegenwoordigt. Het kernidee is vergelijkbaar met het populaire en veelgebruikte idee van woordinbedding in natuurlijke taalverwerking, maar in plaats van woorden, we vertegenwoordigen waarden in de gestructureerde gegevens. Het resultaat is een krachtige oplossing die snel en effectief semantisch zoeken mogelijk maakt in verschillende velden in de database. Een enkele zoekopdracht duurt slechts enkele milliseconden, maar levert resultaten op op basis van honderden miljoenen records en miljarden waarden.
Terwijl we experimenteerden met verschillende neurale netwerkmodellen voor het bouwen van inbeddingen, we verkregen zeer veelbelovende resultaten met behulp van een eenvoudige aanpassing van het originele skip-gram word2vec-model. Dit is een efficiënt ondiep neuraal netwerkmodel gebaseerd op een architectuur die de context (omringende woorden) voorspelt die een woord in een document geeft. In ons werk, we hebben niet te maken met tekstdocumenten, maar met gestructureerde databaserecords. Voor deze, we hoeven niet langer een schuifvenster van een vaste of willekeurige grootte te gebruiken om de context vast te leggen. Bij gestructureerde gegevens de context wordt gedefinieerd door alle waarden in dezelfde rij, ongeacht de kolompositie, aangezien twee aangrenzende kolommen in een database net zo verwant zijn als elke andere twee kolommen. Het andere verschil in onze instellingen is de noodzaak om verschillende velden (of kolommen) in de database vast te leggen. Onze engine moet zowel algemene semantische vragen (d.w.z. retourneert elke databasewaarde gerelateerd aan de gegeven waarde) en veldspecifieke waarden (d.w.z. retourneert waarden uit een bepaald veld gerelateerd aan de invoerwaarde). Voor deze, we wijzen een type toe aan de vectoren die uit elk veld zijn opgebouwd en bouwen een index die typespecifieke of generieke zoekopdrachten ondersteunt.
Krediet:IBM
Voor het werk beschreven in ons artikel, we gebruikten drie publiek beschikbare gebeurtenisdatabases als invoer:GDELT, IJS, en Evenementenregister. Algemeen, deze databases bestaan uit honderden miljoenen records (JSON-objecten of databaserijen) en miljarden waarden in verschillende velden (attributen). Met behulp van onze inbeddingsengine, elke waarde verandert in een vector die de context in de gegevens vertegenwoordigt.
Een eenvoudige ophaalquery
Je kunt zien hoe goed de context wordt vastgelegd door onze engine met behulp van een eenvoudige ophaalquery. Bijvoorbeeld, bij het opvragen van de waarde "Hilary Clinton" (verkeerd gespeld) in veld "person" in GDELT GKG, de eerste treffer of meest gelijkende vector is "Hilary Clinton" (verkeerd gespeld) onder het veld "naam" en de volgende meest gelijkende vectoren zijn "Hillary Clinton" (correcte spelling) onder de velden "persoon" en "naam". Dit komt door de zeer vergelijkbare context van de verkeerd gespelde waarde en de juiste spelling, en ook de waarden in de velden "naam" en "persoon". De rest van de hits voor de bovenstaande zoekopdracht zijn onder meer Amerikaanse politici, vooral degenen die actief waren tijdens de laatste presidentsverkiezingen, evenals aanverwante organisaties, personen met vergelijkbare functies in het verleden, en familieleden.
Gelijkenis zoeken op gecombineerde zoekopdrachten
Natuurlijk, onze oplossing is in staat om veel meer te bereiken dan een simpele opvragingsquery. Vooral, men kan deze zoekopdrachten combineren om een reeks waarden die zijn geëxtraheerd uit een natuurlijke taalquery om te zetten in een vector en een zoekopdracht naar overeenkomsten uit te voeren. We evalueerden het resultaat van deze aanpak met behulp van een benchmark die is gebaseerd op rapporten die zijn geschreven door menselijke experts, en onderzochten het vermogen van onze engine om de concepten die in de rapporten worden beschreven terug te geven met de titel van het rapport als enige input. De resultaten toonden duidelijk de superioriteit van onze op semantische inbedding gebaseerde conceptontdekkingsbenadering in vergelijking met een basislijnbenadering die alleen vertrouwt op het gelijktijdig voorkomen van de waarden.
Nieuwe toepassingen in het ontdekken van concepten
Een zeer interessant aspect van ons raamwerk is dat aan elke waarde en elk veld een vector wordt toegewezen die zijn context vertegenwoordigt, wat nieuwe interessante toepassingen mogelijk maakt. Bijvoorbeeld, we hebben breedte- en lengtecoördinaten van gebeurtenissen in de databases ingebed in dezelfde semantische ruimte van concepten, en werkte samen met het Visual AI Lab onder leiding van Mauro Martino om een visualisatieraamwerk te bouwen dat gerelateerde locaties op een geografische kaart markeert met een vraag in natuurlijke taal. Een andere interessante toepassing die we momenteel onderzoeken, is het gebruik van de opgehaalde concepten en hun semantische inbedding als functies voor een machine learning-model dat de analist moet bouwen. Dit kan worden gebruikt in een geautomatiseerde machine learning en data science (AutoML) engine, en analisten ondersteunen bij een ander belangrijk aspect van hun werk. We zijn van plan deze oplossing te integreren in IBM's Scenario Planning Advisor, een beslissingsondersteunend systeem voor risicoanalisten.
Dit verhaal is opnieuw gepubliceerd met dank aan IBM Research. Lees hier het originele verhaal.
 Wetenschappers ontwikkelen een cellulose-biosensormateriaal voor geavanceerde weefseltechnologie
Wetenschappers ontwikkelen een cellulose-biosensormateriaal voor geavanceerde weefseltechnologie- Wetenschappers maken multifunctionele eiwit-polymeerfilms
- Compound kan energieopslag voor grote netwerken transformeren
- Chemici ontwikkelen veiligere hydrogeneringsprocessen
- Snelle manieren om water te verdampen
Hoofdlijnen
- Microevolution vs Macroevolution: Similiarities & Differences
- Nepal op schema om doel van verdubbeling tijgerpopulatie tegen 2022 te halen
- De nadelen van melkzuurvergisting
- Hoe een TAPPI-kaart te gebruiken
- DNA is digitaal geworden - wat kan er mis gaan?
- Zijn de hersenen bedraad voor religie?
- Vogels onthullen het belang van goede buren voor gezondheid en veroudering
- Nieuwe studie brengt prioriteitsgebieden over de hele wereld in kaart om zoogdieren te beschermen
- Wat gebeurt er met een diercel wanneer deze zich in een hypotone oplossing bevindt?
- Alle dingen kunnen deel uitmaken van het internet der dingen met nieuw RFID-systeem

- YouTube ligt meer dan een uur plat

- Op weg naar een nieuw snelheidsrecord in de Kalahari

- Ransomware-aanval op schapenboeren laat zien dat er geen ruimte is voor wollig denken in cyberbeveiliging

- Duitse rechtbank kan de weg vrijmaken voor een verbod op dieselauto's


 Onderzoekers bedenken nieuwe RNA-nanotechnologie om exosomen te versieren voor effectieve kankertherapie
Onderzoekers bedenken nieuwe RNA-nanotechnologie om exosomen te versieren voor effectieve kankertherapie- Welzijnsvoordelen van wetlands
- De meest actieve vulkaan van IJsland is waarschijnlijk op weg naar een nieuwe uitbarsting
- Chemici ontwikkelen hydrogelsnaren met behulp van verbindingen die in zeedieren worden gevonden
- Easy Chicken Coop-plannen
- Onderzoekers laten zien hoe nanomaterialen voor brandstofcelkathoden kunnen worden geoptimaliseerd
- Hoe de man die de Titanic-plannen vond om Amelia Earhart
- Koolstofstudie in Amazonewoud onthult inheemse gebieden, beschermde gebieden belegerd, toch de beste klimaatoplossing blijven
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | Dutch | Danish | Norway | French | German |

-
Wetenschap © https://nl.scienceaq.com
