Wetenschap
Neurowetenschappers trainen een diep neuraal netwerk om geluiden te verwerken zoals mensen dat doen
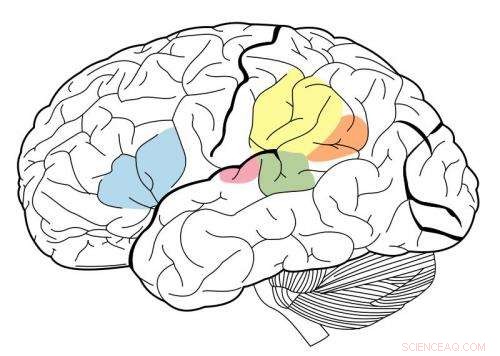
De primaire auditieve cortex is gemarkeerd in magenta, en het is bekend dat het in wisselwerking staat met alle gebieden die op deze neurale kaart zijn gemarkeerd. Krediet:Wikipedia.
Met behulp van een machine learning-systeem dat bekend staat als een diep neuraal netwerk, MIT-onderzoekers hebben het eerste model gemaakt dat menselijke prestaties kan repliceren op auditieve taken, zoals het identificeren van een muziekgenre.
Dit model, die bestaat uit vele lagen informatieverwerkende eenheden die kunnen worden getraind op enorme hoeveelheden gegevens om specifieke taken uit te voeren, werd door de onderzoekers gebruikt om licht te werpen op hoe het menselijk brein dezelfde taken kan uitvoeren.
"Wat deze modellen ons geven, Voor de eerste keer, zijn machinesystemen die zintuiglijke taken kunnen uitvoeren die belangrijk zijn voor mensen en dat doen op menselijk niveau, " zegt Josh McDermott, de Frederick A. en Carole J. Middleton assistent-hoogleraar neurowetenschappen bij de afdeling Hersenen en Cognitieve Wetenschappen aan het MIT en de senior auteur van de studie. "Historisch, dit type sensorische verwerking was moeilijk te begrijpen, deels omdat we niet echt een heel duidelijke theoretische basis hadden en een goede manier om modellen te ontwikkelen van wat er aan de hand zou kunnen zijn."
De studie, die verschijnt in het nummer van 19 april van neuron , biedt ook bewijs dat de menselijke auditieve cortex is gerangschikt in een hiërarchische organisatie, net als de visuele cortex. Bij dit soort arrangementen zintuiglijke informatie doorloopt opeenvolgende stadia van verwerking, met basisinformatie die eerder is verwerkt en meer geavanceerde functies zoals woordbetekenis die in latere stadia worden geëxtraheerd.
MIT-afgestudeerde student Alexander Kell en Stanford University-assistent-professor Daniel Yamins zijn de hoofdauteurs van de paper. Andere auteurs zijn voormalig MIT-bezoekstudent Erica Shook en voormalig MIT-postdoc Sam Norman-Haignere.
De hersenen modelleren
Toen in de jaren tachtig voor het eerst diepe neurale netwerken werden ontwikkeld, neurowetenschappers hoopten dat dergelijke systemen zouden kunnen worden gebruikt om het menselijk brein te modelleren. Echter, computers uit die tijd waren niet krachtig genoeg om modellen te bouwen die groot genoeg waren om echte taken uit te voeren, zoals objectherkenning of spraakherkenning.
In de afgelopen vijf jaar, vooruitgang in rekenkracht en neurale netwerktechnologie hebben het mogelijk gemaakt om neurale netwerken te gebruiken om moeilijke real-world taken uit te voeren, en ze zijn de standaardbenadering geworden in veel technische toepassingen. parallel, sommige neurowetenschappers hebben de mogelijkheid opnieuw bekeken dat deze systemen zouden kunnen worden gebruikt om het menselijk brein te modelleren.
"Dat was een opwindende kans voor de neurowetenschap, in dat we daadwerkelijk systemen kunnen creëren die sommige dingen kunnen doen die mensen kunnen doen, en we kunnen dan de modellen ondervragen en ze vergelijken met de hersenen, ' zegt Kel.
De MIT-onderzoekers trainden hun neurale netwerk om twee auditieve taken uit te voeren, een met spraak en de andere met muziek. Voor de spraakopdracht de onderzoekers gaven het model duizenden opnames van twee seconden van een pratende persoon. De taak was om het woord in het midden van de clip te identificeren. Voor de muziekopdracht het model werd gevraagd om het genre van een muziekclip van twee seconden te identificeren. Elke clip bevatte ook achtergrondgeluid om de taak realistischer (en moeilijker) te maken.
Na vele duizenden voorbeelden, het model leerde de taak net zo nauwkeurig uit te voeren als een menselijke luisteraar.
"Het idee is dat het model na verloop van tijd steeds beter wordt in de taak, " zegt Kell. "De hoop is dat het iets algemeens leert, dus als je een nieuw geluid presenteert dat het model nog nooit eerder heeft gehoord, het zal goed gaan, en in de praktijk is dat vaak het geval."
Het model had ook de neiging om fouten te maken op dezelfde clips waarop mensen de meeste fouten maakten.
De verwerkingseenheden waaruit een neuraal netwerk bestaat, kunnen op verschillende manieren worden gecombineerd, het vormen van verschillende architecturen die de prestaties van het model beïnvloeden.
Het MIT-team ontdekte dat het beste model voor deze twee taken er een was die de verwerking in twee reeksen fasen verdeelde. De eerste reeks fasen werd gedeeld tussen taken, maar daarna, het splitste zich in twee takken voor verdere analyse:een tak voor de spraaktaak, en één voor de taak van het muzikale genre.
Bewijs voor hiërarchie
De onderzoekers gebruikten hun model vervolgens om een al lang bestaande vraag over de structuur van de auditieve cortex te onderzoeken:of deze hiërarchisch is georganiseerd.
In een hiërarchisch systeem, een reeks hersengebieden voert verschillende soorten berekeningen uit op sensorische informatie terwijl deze door het systeem stroomt. Het is goed gedocumenteerd dat de visuele cortex dit type organisatie heeft. eerdere regio's, bekend als de primaire visuele cortex, reageren op eenvoudige kenmerken zoals kleur of oriëntatie. Latere stadia maken complexere taken mogelijk, zoals objectherkenning.
Echter, het was moeilijk om te testen of dit type organisatie ook bestaat in de auditieve cortex, deels omdat er geen goede modellen zijn geweest die menselijk auditief gedrag kunnen repliceren.
"We dachten dat als we een model konden bouwen dat dezelfde dingen zou kunnen doen als mensen, we zouden dan in staat kunnen zijn om verschillende stadia van het model te vergelijken met verschillende delen van de hersenen en enig bewijs te krijgen voor de vraag of die delen van de hersenen hiërarchisch georganiseerd zouden kunnen zijn, ' zegt McDermott.
De onderzoekers ontdekten dat in hun model, basiskenmerken van geluid, zoals frequentie, zijn in de vroege stadia gemakkelijker te extraheren. Naarmate informatie wordt verwerkt en verder langs het netwerk beweegt, het wordt moeilijker om frequentie te extraheren, maar gemakkelijker om informatie op een hoger niveau, zoals woorden, te extraheren.
Om te zien of de modelstadia kunnen repliceren hoe de menselijke auditieve cortex geluidsinformatie verwerkt, de onderzoekers gebruikten functionele magnetische resonantie beeldvorming (fMRI) om verschillende regio's van de auditieve cortex te meten terwijl de hersenen echte geluiden verwerken. Vervolgens vergeleken ze de hersenreacties met de reacties in het model toen het dezelfde geluiden verwerkte.
Ze ontdekten dat de middelste stadia van het model het beste overeenkwamen met de activiteit in de primaire auditieve cortex, en latere stadia kwamen het best overeen met activiteit buiten de primaire cortex. Dit levert bewijs dat de auditieve cortex op een hiërarchische manier kan zijn gerangschikt, vergelijkbaar met de visuele cortex, zeggen de onderzoekers.
"Wat we heel duidelijk zien, is een onderscheid tussen de primaire auditieve cortex en al het andere, ' zegt McDermott.
De auteurs zijn nu van plan om modellen te ontwikkelen die andere soorten auditieve taken kunnen uitvoeren, zoals het bepalen van de locatie waar een bepaald geluid vandaan kwam, om te onderzoeken of deze taken kunnen worden uitgevoerd door de paden die in dit model zijn geïdentificeerd of dat ze afzonderlijke paden vereisen, die vervolgens in de hersenen kunnen worden onderzocht.
 Energiestroom en chemische cyclus door Ecosystem
Energiestroom en chemische cyclus door Ecosystem- Wat gebeurt er als de zeespiegel stijgt en kustland onder water komt te staan?
- Californië brengt nieuwe klimaatwetenschap uit, planningstools ter voorbereiding op de gevolgen van klimaatverandering
- De invloed van de opwarming van de aarde op extreme weersomstandigheden wordt vaak onderschat
- Een koraalrif maken Science Project
Hoofdlijnen
- Het leefgebied van de panda krimpt, steeds meer gefragmenteerd worden
- Het verschil tussen hoe interne en externe regulatoren werken
- Hoe groeit schimmel op voedsel?
- Hoe de botten in het menselijk skelet te bestuderen
- Onderzoeker ontdekt dat wanneer sperma concurreert, eieren hebben een keuze
- Minder herkauwen, meer vergroening van de brandstof
- Zullen we binnenkort uitgestorven zijn?
- High School Biology Experiment Ideas
- Waarom is chemie belangrijk voor de studie van anatomie en fysiologie?
- Nieuwe EU-regels laten je Netflix kijken, BBC in het buitenland

- Nieuw filter verbetert het robotzicht op 6-D pose-schatting

- Airbus en Dassault werken samen aan gevechtsjager

- Ierland recupereert 14 miljard euro aan achterstallige Apple belastingen

- Nieuw model biedt meer details over het wiegen van de Millennium Bridge


 Hoe u punthellingsvorm naar hellingsonderscheiding converteren Form
Hoe u punthellingsvorm naar hellingsonderscheiding converteren Form- Hoe steenslag kan helpen kooldioxide op te vangen
- Onderzoekers zoeken naar manier om zonnecellen ultradun te maken, flexibel
- Astronomen voeren een uitgebreide studie uit van jonge open sterrenhoop NGC 1960
- Een quantum dot energy harvester:afvalwarmte omzetten in elektriciteit op nanoschaal
- Moleculen uit het water of de lucht filteren met nanomembranen
- Explainer:hoe de zoekresultaten van Google werken
- Verkenning van de oceaan onthult een van Cuba's verborgen natuurlijke schatten
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
