Wetenschap
Onder de radar:op zoek naar onopvallende supersymmetrie

Krediet:CERN
Het standaardmodel van de deeltjesfysica omvat onze huidige kennis van elementaire deeltjes en hun interacties. Het standaardmodel is niet compleet; bijvoorbeeld, het beschrijft geen waarnemingen zoals zwaartekracht, heeft geen voorspelling voor donkere materie, waaruit de meeste materie in het universum bestaat, of dat neutrino's massa hebben.
Om de zwakke punten van het standaardmodel op te lossen, natuurkundigen stellen uitbreidingen voor en controleren de botsingen bij de LHC om te zien of voorspellingen van die modellen van "fysica voorbij het standaardmodel" zouden verschijnen als nieuwe deeltjes of veranderingen in het gedrag van bekende deeltjes. supersymmetrie, of kortweg SUSY, is een van die uitbreidingen van het standaardmodel. Supersymmetrie voorspelt dat elk bekend deeltjetype in het standaardmodel een supersymmetrische partner heeft. Het aantal deeltjestypes in de natuur zou dan effectief verdubbeld zijn, en veel nieuwe interacties tussen de reguliere deeltjes en de nieuwe SUSY-deeltjes zouden mogelijk zijn.
Bij een Collider-experiment zoals CMS, de hoop is om enkele SUSY-deeltjes te produceren en vervolgens in de detector naar tekenen van verval te zoeken. Een van de meest voorkomende kenmerken van supersymmetrie zou worden gemeten als schijnbaar ontbrekende deeltjes die een aanzienlijke energie-onbalans in de detector veroorzaken, de zogenaamde ontbrekende transversale energie. Dit is een handtekening in de definitieve staat die moeilijk te missen is!
Er hebben veel zoekopdrachten plaatsgevonden bij CMS om te zoeken naar deze hoge ontbrekende transversale energiesignaturen, maar geen dergelijk bewijs voor supersymmetrie is gevonden. Maar, misschien is er supersymmetrie, en het is gewoon "stealthier" dan aanvankelijk werd gedacht. Er zijn veel verschillende mogelijke handtekeningen die supersymmetrie zou kunnen creëren, en in sommige aangepaste versies van supersymmetrie, een belangrijk kenmerk is de voorspelling dat alle SUSY-deeltjes terug zouden vervallen tot standaardmodeldeeltjes, bijvoorbeeld, quarks, die elk in de detector zouden verschijnen als een nevel van deeltjes, wat een jet wordt genoemd. Als deze versie van supersymmetrie echt is, De productie van SUSY-deeltjes bij een proton-protonbotsing zal resulteren in een eindtoestand met veel jets in plaats van een met een aanzienlijk ontbrekende energie. In dit geval, het zou logisch zijn waarom deze eerdere zoekopdrachten niets hebben gevonden!
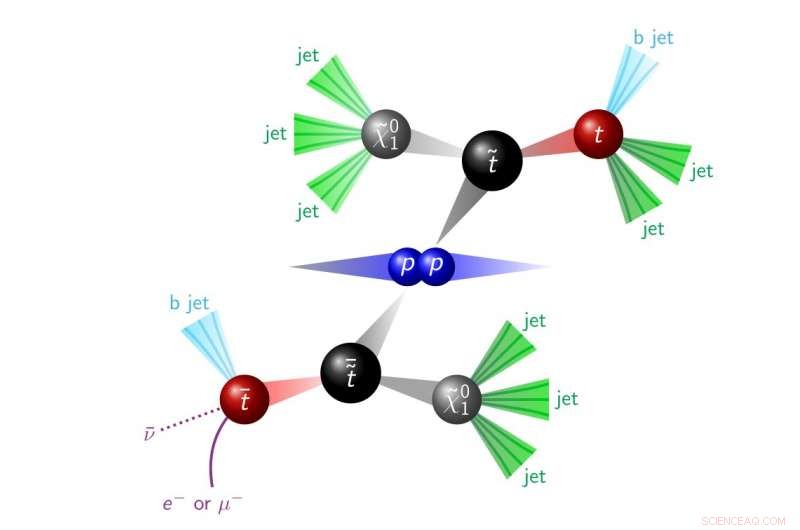
Figuur 1. Een dramatisering van een proton-protonbotsing die SUSY-deeltjes produceert, die vervallen tot objecten die in de detector worden waargenomen (dit is een handtekening voor de zogenaamde R-pariteit die SUSY schendt). Krediet:CERN
Het doel van deze zoektocht is om erachter te komen of supersymmetrie zich daar al dan niet heeft verstopt door specifiek te zoeken naar de productie van twee supersymmetrische top-quarks (de zogenaamde top-squarks). Deze top squarks vervallen in de detector, het creëren van twee top-quarks en vele andere jets, zoals weergegeven in figuur 1. Deze signatuur is niet zo duidelijk als een signatuur die grote hoeveelheden ontbrekende energie bevat, aangezien er veel verschillende manieren zijn waarop het standaardmodel twee top-quarks en veel jets kan produceren. Echter, dit top-squark-signaal heeft de neiging om gemiddeld meer jets te maken dan alle bekende achtergrondprocessen. Het modelleren van evenementen met een zeer groot aantal jets is ook erg lastig, en zelfs de beste simulatietools doen het niet altijd goed. Daarom, op gegevens wordt vertrouwd om het aantal gebeurtenissen met een bepaald aantal jets te voorspellen.
Onze strategie zou niet mogelijk zijn geweest zonder gebruik te maken van de kracht van machine learning en neurale netwerken. Een coole machine learning-techniek die werd gebruikt om botsingen te identificeren die het verval van topsquarks kunnen bevatten, wordt gradiëntomkering genoemd. wat op de volgende manier kan worden uitgelegd. Stel je voor dat je chocolaatjes in twee categorieën sorteert:chocolaatjes met karamel en gewone chocolaatjes. Je weet dat karamel bonbons zwaarder zijn dan gewone bonbons omdat ze gevuld zijn met karamel. Laten we ook zeggen dat de chocolaatjes er maar in twee vormen zijn tussen alle karamel- en gewone varianten:vierkanten of cirkels. Eindelijk, er wordt je verteld dat de vierkante chocolaatjes zijn, gemiddeld, zwaarder dan de ronde.
Een manier om de chocolaatjes te sorteren is om alle vierkante chocolaatjes te sorteren als karamelpralines en alle ronde chocolaatjes als gewone chocolaatjes. Ten slotte, zowel vierkante bonbons als karamelchocolade zijn over het algemeen zwaarder. Deze sorteerbenadering is niet correct omdat niet alle vierkante chocolaatjes karamel bevatten, dus het is waarschijnlijk beter om de chocolaatjes onafhankelijk van hun vorm te sorteren. Het negeren van vorm bij het sorteren komt overeen met wat we met gradiëntomkering kunnen doen in de natuurkundige context. In plaats van karamel en gewone chocolaatjes, de sortering is tussen signaal- en achtergrondgebeurtenissen, en in plaats van vorm, de sortering dient onafhankelijk te zijn van het aantal jets.
Deze strategie is precies wat nodig is om de verdeling van het aantal jets direct uit de data te modelleren. Gebeurtenissen in de achtergrondcategorie worden gebruikt om te voorspellen hoeveel gebeurtenissen er moeten zijn met een bepaald aantal jets in de signaalcategorie. Aangezien het signaalmodel de neiging heeft om meer jets te produceren dan de achtergronden van het standaardmodel, elke afwijking van de voorspelling zou kunnen betekenen dat daar inderdaad een SUSY verstopt zat.
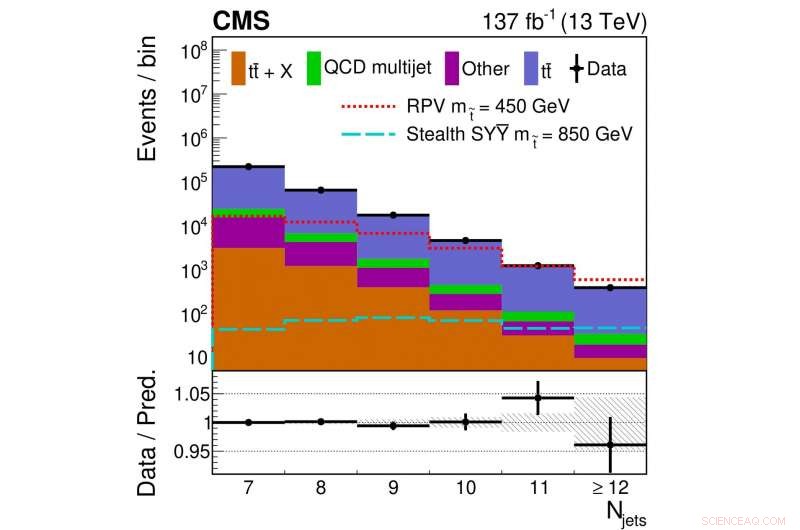
Figuur 2. De verdeling van het aantal gebeurtenissen met een bepaald aantal jets is weergegeven voor de verzamelde gegevens (zwarte punten) en de voorspelde bijdragen van bekende standaardmodelachtergronden (gekleurde blokken). Verschillende gekleurde/gestileerde lijnen tonen de verdeling van het aantal jets voor verschillende SUSY-modellen met specifieke top-squark-massa's.
Figuur 2 toont een vergelijking van het aantal jets-distributie verkregen uit de verzamelde gegevens met die van onze uiteindelijke achtergrondvoorspelling. In dit geval, de voorspelling gaat ervan uit dat er geen bijdrage is van onze veronderstelde signaalmodellen. Hier, de overeenkomst tussen gegevens en onze voorspelling uit vier categorieën standaardmodelprocessen is redelijk goed.
Wanneer de gegevens worden onderverdeeld in meer categorieën dan weergegeven in figuur 2, er wordt een kleine afwijking van onze voorspelling gevonden. Echter, de afwijking is niet groot genoeg om een sterke bewering te doen of dit al dan niet aangeeft dat supersymmetrie correct zou kunnen zijn. Het is zeer waarschijnlijk dat er slechts een statistische fluctuatie in de gegevens was, of misschien dat er een onbekend modelleringsprobleem is.
In de deeltjesfysica, de "gouden standaard" is om een ontdekking van nieuwe fysica aan te kondigen wanneer een resultaat een significantie heeft van 5 standaarddeviaties of groter. Dit betekent dat er slechts een kans van 1 op 3,5 miljoen is dat het resultaat slechts een willekeurige fluctuatie in gegevens is. Bewijs, of beweren dat iets interessant genoeg is om de mogelijkheid te overwegen dat het nieuw zou kunnen zijn, wordt alleen gedaan met een significantie van 3 standaarddeviaties, wat neerkomt op een kans van 1 op 740 dat het resultaat een fluctuatie is. Deze norm is zeer streng in vergelijking met de meeste andere wetenschappelijke disciplines. De LHC produceert een enorme hoeveelheid data, het kan dus inderdaad gebeuren dat een afwijking van de standaardmodelvoorspelling door toeval wordt verkregen. In de deeltjesfysica, het is zeker niet gerechtvaardigd om enige afwijking te claimen zonder de statistische validiteit ervan serieus te onderzoeken.
De significantie van de grootste afwijking die werd waargenomen in deze analyse, zonder correctie voor het look elders effect, is 2,8 standaarddeviaties. Dit betekent dat zelfs als er geen supersymmetrie is, men verwacht zo'n resultaat eens in de 368 keer te zien, ruim onder de drempel van 5 standaarddeviatie. Aangezien CMS meer dan 1000 artikelen heeft gepubliceerd, velen kijken op tientallen of honderden plaatsen, je ziet dat een incidentele fluctuatie in een resultaat helemaal niet verwonderlijk is. De resultaten kunnen ook worden geïnterpreteerd als een limiet voor de toegestane onopvallende supersymmetriescenario's die nog steeds consistent zijn met de gegevens. Afhankelijk van de details van het model, top squark massa's onder ~ 700 GeV kunnen worden uitgesloten.
Deze zoektocht is de eerste in zijn soort bij de LHC, licht werpen op een voorheen onontgonnen signatuur. De gevonden kleine discrepantie is verleidelijk en nodigt uit tot vervolgstudies om te onderzoeken of de oorsprong ervan een eenvoudige statistische fluctuatie is, of het komt door ons begrip van het standaardmodel, wat op zichzelf al interessant zou zijn, of dat het het eerste teken van nieuwe fysica zou kunnen zijn. Ook, vanaf 2022, de volgende gegevensverzamelingsperiode van de LHC begint. Dit zal CMS helpen om nog sterkere conclusies te trekken over de mogelijkheid van nieuwe fysica. Als stiekeme supersymmetrie er echt is, dan zouden deze extra gegevens een significanter resultaat mogelijk maken, mogelijk op weg naar de gouden standaard voor ontdekking.
 Leuphana-wetenschappers ontwikkelen milieuvriendelijkere antibiotica
Leuphana-wetenschappers ontwikkelen milieuvriendelijkere antibiotica- Het voorkomen van zuurstofafgifte leidt tot veiligere batterijen met een hoge energiedichtheid
- Elektrostatische kracht neemt de leiding in bio-geïnspireerde polymeren
- Perovskiet-oplossing veroudering:wetenschappers vinden oplossing
- De groene revolutie naar elektronica brengen
- veengebieden, al aan het slinken, zou kunnen worden geconfronteerd met verdere verliezen
- Duurzaamheid van het voedselsysteem vereist een lager energieverbruik
- Luchtfoto's onthullen een onzichtbare fout in Chinese stad
- Ondanks hoge verwachtingen, de koolstof die wordt geabsorbeerd door het herstel van het Amazonewoud valt in het niet bij de uitstoot van ontbossing
- Verboden! New York stuurt plastic zakken inpakken
Hoofdlijnen
- Een parasiet volgen die vissen verwoest
- Waarom hebben de meeste mensen 23 paar chromosomen?
- Cellulaire ademhaling bij de mens
- Hoe een menselijke cel te maken voor een wetenschapsproject
- Welke invloed heeft veroudering op de mogelijkheid om homeostase te herstellen?
- Wat levert elektronen voor de lichtreacties?
- Een driedimensionaal model van een plantencel maken met labels
- De Krebs-cyclus gemakkelijk gemaakt
- Wat is de relatie tussen genetische manipulatie en DNA-technologie?
- Herziening van multiferroics voor de toekomst, energiezuinige gegevensopslag

- Wetenschappers ontdekken principes van universele zelfassemblage
- LHC bereikt recordhelderheid

- Superisolatoren worden wetenschappers quark-speeltuinen
- Hoe paardenbloemzaden fungeren als een perfecte pipet in het laboratorium


 Heeft Pluto stormen?
Heeft Pluto stormen? - Een stad ontwerpen zonder auto's - in het belang van de kinderen
- Toyota, Panasonic vormt joint venture in huisvesting voor Japan
- Wetenschappers ontdekken 500 meter hoog koraalrif in het Great Barrier Reef, de eerste die in meer dan 120 jaar is ontdekt
- Polymeercoating koelt gebouwen af
- Stroom meten met een oscilloscoop
- Wi-Fi-signalen omzetten in elektriciteit met nieuwe 2D-materialen
- De ellende van Merkel neemt toe als minister van Landbouw orders negeert (update)
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | German | Dutch | Danish | Swedish | Norway |

-
Wetenschap © https://nl.scienceaq.com
