Wetenschap
Een nieuw model om afbeeldingen op basis van schetsen op te halen
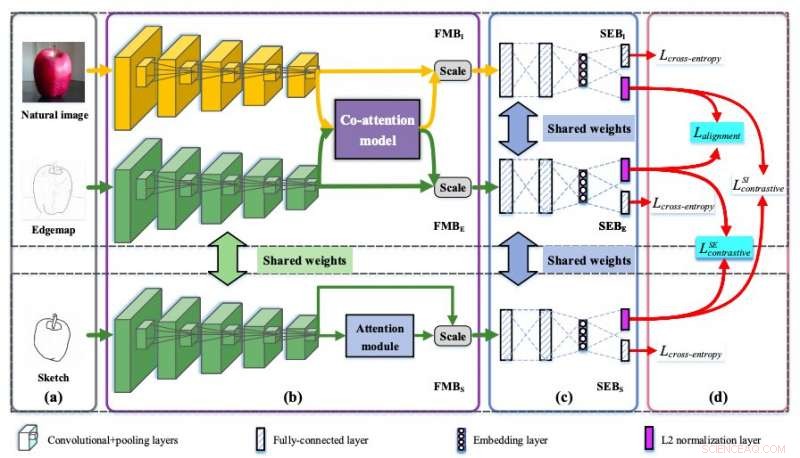
Illustratie van Semi3-Net-architectuur. Krediet:Lei et al.
In recente jaren, onderzoekers hebben steeds geavanceerdere rekentechnieken ontwikkeld, zoals deep learning-algoritmen, om verschillende taken uit te voeren. Een taak die ze probeerden aan te pakken, staat bekend als "schets-based image retrieval" (SBIR).
SBIR-taken omvatten het ophalen van afbeeldingen van een bepaald object of visueel concept uit een brede collectie of database op basis van schetsen gemaakt door menselijke gebruikers. Om deze taak te automatiseren, onderzoekers hebben geprobeerd hulpmiddelen te ontwikkelen die menselijke schetsen kunnen analyseren en afbeeldingen kunnen identificeren die gerelateerd zijn aan de schets of hetzelfde object bevatten.
Ondanks de veelbelovende resultaten die met sommige van deze instrumenten zijn bereikt, het ontwikkelen van technieken die consistent goed presteren op SBIR-taken is tot nu toe een uitdaging gebleken. Dit komt vooral door de grote visuele verschillen tussen abstracte schetsen en echte afbeeldingen. Bijvoorbeeld, door mensen gemaakte schetsen zijn vaak vervormd en abstract, waardoor ze moeilijker te relateren zijn aan objecten in echte afbeeldingen.
Om deze uitdaging te overwinnen, onderzoekers van Tianjin University en Beijing University of Posts and Telecommunications in China hebben onlangs een op neurale netwerken gebaseerde architectuur ontwikkeld die discriminerende domeinoverschrijdende functierepresentaties leert voor op schets gebaseerde taken voor het ophalen van afbeeldingen (SBIR). De techniek die ze ontwikkelden, gepresenteerd in een paper dat vooraf is gepubliceerd op arXiv, combineert verschillende rekentechnieken, inclusief semi-heterogene feature mapping, gezamenlijke semantische inbedding en co-aandachtsmodellen.
"Het belangrijkste inzicht ligt in hoe we de wederzijdse en subtiele relaties tussen de schetsen cultiveren, natuurlijke afbeeldingen en edgemaps, ", schreven de onderzoekers in hun paper. "Semi-heterogene feature mapping is ontworpen om bodemkenmerken uit elk domein te extraheren, waar de schets- en edgemap-takken worden gedeeld, terwijl de natuurlijke afbeeldingstak heterogeen is voor andere takken."
Het door de onderzoekers ontworpen model is een semi-heterogeen drieweg joint inbeddingsnetwerk (Semi3-Net). Naast semi-heterogene mapping, het maakt gebruik van een techniek die bekend staat als gezamenlijke semantische inbedding. Met semantische inbedding kan het netwerk functies van verschillende domeinen insluiten (bijv. van schetsen of foto's) in een gemeenschappelijke semantische ruimte op hoog niveau. Semi3-Net bevat ook een mede-aandachtsmodel, die is ontworpen om functies die zijn geëxtraheerd uit de twee verschillende domeinen opnieuw te kalibreren.
Eindelijk, ontwierpen de onderzoekers een hybride-verliesmechanisme dat de correlatie tussen schetsen kan berekenen, edgemaps en natuurlijke afbeeldingen. Met dit mechanisme kan het Semi3-Net-model representaties leren die invariant zijn over de twee domeinen (d.w.z. schetsen en foto's gemaakt met camera's).
De onderzoekers trainden en evalueerden Semi3-Net op gegevens van Sketchy en TU-Berlin Extension, twee datasets die veel worden gebruikt in onderzoeken die zich richten op SBIR-taken. De Sketchy-database bevat 75, 471 schetsen en 12, 500 natuurlijke afbeeldingen, terwijl TU-Berlin Extension 204 bevat, 489 natuurlijke beelden en 20, 000 handgetekende schetsen.
Tot dusver, Semi3-Net heeft opmerkelijk goed gepresteerd in alle experimenten die door de onderzoekers zijn uitgevoerd, beter presteren dan andere state-of-the-art modellen voor SBIR. Het team is nu van plan om verder te werken aan het model en de prestaties ervan verder te verbeteren. misschien zelfs om het aan te passen om andere problemen aan te pakken die het verbinden van gegevens uit verschillende domeinen vereisen.
"In de toekomst, we zullen ons concentreren op het uitbreiden van het voorgestelde cross-domein netwerk naar fijnkorrelig ophalen van afbeeldingen en het leren van de correspondentie van de fijnkorrelige details voor schets-beeldparen, ’ schreven de onderzoekers in hun paper.
© 2019 Wetenschap X Netwerk
 Bicyclische eiwitmimetica remmen het oncogen β-catenine
Bicyclische eiwitmimetica remmen het oncogen β-catenine- Klinische tests tonen aan dat biosensoren in de toekomst de weg kunnen effenen voor een gepersonaliseerde antibiotherapie
- Nieuw covalent organisch raamwerk met boor en fosfor zorgt voor betere connectiviteit
- Video:Waarom haten sommige mensen koriander?
- Chemici zetten titanium nanodeeltjes om in een efficiënt wapen tegen vervuiling
- Spanje schopt uit sneeuwbanken achtergelaten door storm Filomena
- Suomi NPP vindt ongeorganiseerde stormen in tropische depressie 29W
- Computermodel toont uiteenvallen ijsbergblokkades
- Experimenten tonen aan dat het record van het vroege leven vol valse positieven kan zijn
- De cyclus van zuurstof door een ecosysteem
Hoofdlijnen
- Er zit een diepere vis in de zee
- Hoe reproduceren algen?
- De adelaars scouten:het bewijs dat het beschermen van nesten de voortplanting bevordert
- Hogere biodiversiteit door rivierverruimende maatregelen
- Wat u moet weten over mitose voor een test
- Een beschrijving van het doel van mitose
- Zien in het donker - hoe plantenwortels water waarnemen door middel van groei
- Septate vs. Non-Septate Hyphae
- Hoe een tRNA-reeks te krijgen van een DNA-reeks
- Thomas Cook-aandelen stijgen op bij biedingsaanpak Fosun

- Deze robots zijn klein, vormveranderend, en ze passen zich aan hun omgeving aan

- Eerste proeven van innovatieve, niet-invasieve minerale exploratietechnologieën

- Qualcomm verhoogt bod op NXP tot ongeveer $ 43,22 miljard

- PSA, Fiat Chrysler onthult fusie van gelijken


 Hoe Pleo werkt
Hoe Pleo werkt - Het opschalen van het zoeken naar analogieën kan de sleutel zijn tot innovatie
- Lyft duwt in fietsen met nieuwe aanwinst
- NASA's Aqua-satelliet vindt winden die de tropische cycloon Gelena teisteren
- Drugsrechtbank verkleint kans op recidive op lange termijn, nieuwe onderzoeksresultaten
- Het grootste virtuele universum ooit gesimuleerd
- Uitvinding aangewakkerd door COVID-19-pandemie desinfecteert continu veilig oppervlakken
- Volume berekenen in kubieke centimeter
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Spanish | Portuguese | Swedish | German | Dutch | Norway | Italian | Danish |

-
Wetenschap © https://nl.scienceaq.com
