Wetenschap
De tijd die nodig is om de belangrijkste moleculen te sequensen, kan worden teruggebracht van jaren tot minuten
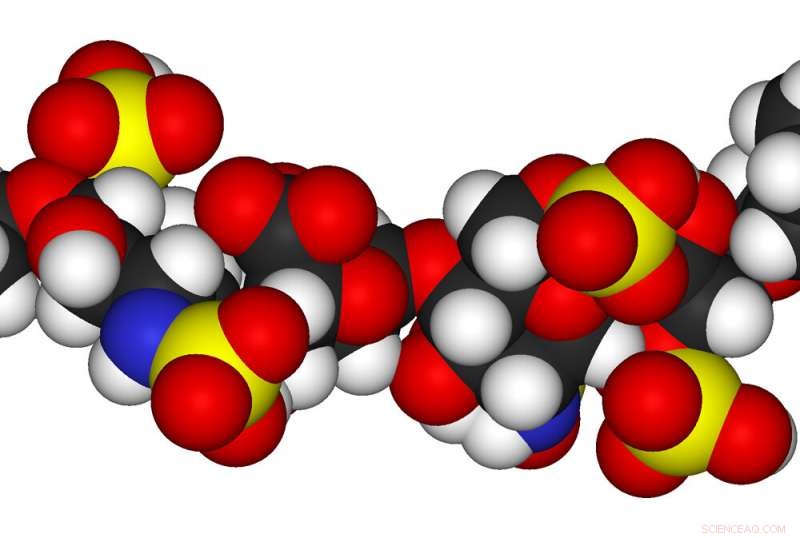
Een nanoporie- en beeldherkenningssoftware kan een gesulfateerde glycosaminoglycaan in realtime sequencen. Krediet:Rensselaer Polytechnisch Instituut
Met behulp van een nanoporie, onderzoekers hebben het potentieel aangetoond om de tijd die nodig is voor het sequencen van een glycosaminoglycaan - een klasse van suikermoleculen met lange ketens die net zo belangrijk zijn voor onze biologie als DNA - te verminderen van jaren tot minuten.
Zoals deze week gepubliceerd in de Proceedings van de National Academies of Sciences , een team van het Rensselaer Polytechnic Institute toonde aan dat machine learning en beeldherkenningssoftware kunnen worden gebruikt om suikerketens snel en nauwkeurig te identificeren, met name, vier synthetische heparansulfaten - gebaseerd op de elektrische signalen die werden gegenereerd toen ze door een klein gaatje in een kristalwafeltje gingen.
"Glycosaminoglycanen zijn een complex repertoire van sequenties, zoals het werk van Shakespeare of een gedicht van Yates een complexe verzameling brieven is. Er is een expert voor nodig om ze te schrijven en een expert om ze te lezen, " zei Robert Linhardt, hoofdonderzoeker en hoogleraar scheikunde en chemische biologie aan het Rensselaer Polytechnic Institute. "We hebben een machine getraind om snel het equivalent van woorden met vier letters zoals 'ababab' of 'bcbcbc' te lezen. Dit zijn eenvoudige reeksen die geen betekenis hebben, maar ze laten ons zien dat de machine kan worden geleerd om te lezen. Als we deze technologie uitbreiden en ontwikkelen, het heeft het potentieel om de glycanen of zelfs eiwitten in realtime te sequencen, het elimineren van jaren van inspanning."
Commerciële apparaten voor het sequencen van nanoporiën worden gebruikt om DNA te sequensen, die is samengesteld uit vier nucleïnezuureenheden, bekend onder de letters A, C, G, en T, aaneengeregen in een eindeloze verscheidenheid aan configuraties. Het apparaat vertrouwt op een ionische stroom die door een gat van slechts enkele miljardsten van een meter breed in een membraan loopt. Aan één kant van het gat worden strengen DNA geplaatst, en meegezogen met de stroom van de stroom. Elk nucleïnezuur blokkeert het gat enigszins als het er doorheen gaat, het verstoren van de stroom en het opleveren van een bepaald signaal dat is geassocieerd met dat nucleïnezuur. de apparaten, momenteel gebruikt voor veldwerk, zijn slechts een van de vele relatief snelle en geautomatiseerde technieken voor het sequencen van DNA.
Glycosaminoglycanen, of GAG's, zijn een structureel complexe klasse van glycanen - de essentiële suikers die aanwezig zijn in levende organismen - die worden aangetroffen op de celoppervlakken en extracellulaire matrix van alle dieren en die vele functies vervullen bij celgroei en signalering, antistolling en wondherstel, en het handhaven van celadhesie. GAG's, momenteel gewonnen uit geslachte dieren, worden gebruikt als medicijnen en nutraceuticals.
Zoals DNA, GAG's kunnen worden onderverdeeld in hun samenstellende disacharidesuikereenheden. Maar terwijl DNA bestaat uit slechts vier letters in een lineaire reeks, deze glycanen hebben tientallen basiseenheden, sommige met aangehechte sulfaatgroepen, zuur groepen, en amidegroepen. Bijvoorbeeld, zelfs een relatief klein natuurlijk voorkomend heparansulfaatmolecuul van zes suikereenheden zou er 32 kunnen hebben, 768 mogelijke reeksen. Vanwege de uitdaging glycan-sequencing blijft lastig, vertrouwen op nauwgezet laboratoriumwerk en geavanceerde analyse, met technieken met namen als vloeistofchromatografie-tandemmassaspectrometrie en kernmagnetische resonantiespectroscopie.
Als onderdeel van zijn werk, Linhardt, een glycanenexpert die een synthetische variant van de veelvoorkomende bloedverdunner heparine ontwikkelde, sequenties GAG's om natuurlijk voorkomende vormen te begrijpen en synthetische varianten te ontwikkelen.
"Met behulp van standaard analytische methoden, het kostte ons twee jaar om de eerste simpele GAG te sequencen, " zei Linhardt, een lid van het Rensselaer Centrum voor Biotechnologie en Interdisciplinaire Studies. "We hebben er nog een waarvan we het grootste deel van de reeks hebben uitgewerkt, en het heeft ons meer dan vijf jaar gekost - en het zal ons waarschijnlijk nog vijf jaar kosten om het af te maken, "
Redeneren dat nanopore-sequencing kan worden gebruikt om de disaccharide-eenheden in een GAG te identificeren, het onderzoeksteam bouwde zijn eigen nanopore-apparaat en synthetiseerde vier heparansulfaat GAG-ketens met behulp van het chemo-enzymatische proces dat is ontwikkeld door het Linhardt Lab. belangrijk, deze vier heparansulfaten waren heel eenvoudig - gemaakt met combinaties van slechts vier verschillende soorten suikereenheden, geassembleerd in een ketting van ongeveer 40 eenheden lang, en met een zorgvuldig gecontroleerde compositie en volgorde.
Het team passeerde elk heparansulfaat door de nanoporie en produceerde een grafiek die de spanning in de loop van de tijd van het apparaat weergeeft. Elk van de vier varianten werd meer dan 2 door het apparaat uitgevoerd, 000 keer, het vergroten van de statistische waarschijnlijkheid van een nauwkeurige aflezing gezien het rudimentaire ontwerp van de experimentele nanoporie.
"Het apparaat analyseerde in realtime het eenvoudigste heparansulfaat en produceerde een patroon dat onze ogen gemakkelijk meteen konden herkennen voor elk van de vier monsters, "Zei Linhardt. "Je ziet meteen dat ze anders zijn."
Om een onbevooroordeelde analyse te garanderen, het team heeft de resultaten ingevoerd in gratis software voor machine learning en beeldherkenning met behulp van het diepe neurale netwerk van Google, de software trainen om onderscheid te maken tussen de vier verschillende patronen en elke variant van heparansulfaat te identificeren. Het meest succesvolle machine learning-model leverde een analyse op die bijna 97% nauwkeurig was.
"De informatie-inhoud in een GAG-sequentie kan die van een vergelijkbare hoeveelheid DNA of RNA aanzienlijk overtreffen, wat betekent dat het vermogen om snel GAG-sequenties te lezen een nieuw venster van inzicht opent in de complexe biochemie van het leven", zei Curt Breneman, decaan van de Rensselaer School of Science. "Deze proof-of-concept-studie koppelt innovatieve nanodetectiemethoden aan geavanceerde machine learning-tools, en toont de kracht van interdisciplinair denken om de grenzen van kennis te verleggen."
Het verminderen van de snelheid waarmee de GAG's door de nanoporiën gaan, zou de nauwkeurigheid kunnen vergroten, en het apparaat kan worden getraind op extra suikereenheden, en meer complexe sequenties, dit zijn allemaal toekomstige onderzoeksdoelen. Linhardt zei dat de machine ergens tussen de 10 en 20 suikereenheden zou moeten leren om een GAG volledig te sequencen.
"Dit is een proof of concept; we hebben woorden van twee letters laten lezen, "Zei Linhardt. "Zodra we het het volledige alfabet leren, het zal in staat zijn om elke verschillende reeks te lezen. Het zal in staat zijn om alle woorden te lezen."
 Potentieel alternatief voor petroleumpolycarbonaat dat bronnen van omgevingshormonen bevat
Potentieel alternatief voor petroleumpolycarbonaat dat bronnen van omgevingshormonen bevat- Een materiaalwetenschappelijke benadering van de bestrijding van het coronavirus
- Zelfgemaakte Glow Sticks maken
- Hoe een driedimensionale Atom
- Moleculaire poriën kunnen de efficiëntie van olieraffinage en farmaceutische productie verbeteren
Hoofdlijnen
- Depolarisatie en herpolarisatie van het celmembraan
- Celmotiliteit: wat is het? & Waarom is het belangrijk?
- DropSynth, een eenpotsbenadering van gensynthese
- Verschuivende aanwezigheid van Noord-Atlantische walvissen gevolgd met passieve akoestiek
- Hoe werkt ruw ER met Ribosomes?
- Röntgenfoto's van het skelet van Dolly vertonen geen tekenen van abnormale artrose
- Kweek vers voedsel in uw huis - verticaal
- Waarom wordt magnesiumchloride gebruikt in PCR?
- Maak een lijst van de 3 stappen die optreden tijdens de interfase
- Chemische ingenieurs ontwikkelen nieuwe klasse multifunctioneel precisiepolymeer

- Ultrasnelle lasers onderzoeken ongrijpbare chemie op het vloeistof-vloeistofgrensvlak

- Het bouwen van zetmeelruggengraat voor in het laboratorium gekweekt vlees met behulp van Lego-stukken

- Een gewoon plastic omzetten in hoogwaardige moleculen

- Het potentieel van niet-giftige materialen om lood in perovskietzonnecellen te vervangen


 De verborgen gegevens in uw vingerafdrukken
De verborgen gegevens in uw vingerafdrukken- Zending ruimtestation gelanceerd vanaf de kust van Virginia
- Hoe de nauwkeurigheid van metingen te berekenen
- Stageprogramma's van de overheid zijn kwetsbaar, volgens nieuw onderzoek
- Biden, Warren stelt nieuwe plannen voor om klimaatverandering tegen te gaan
- Onderzoekers beschermen hardware tegen cyberaanvallen
- Definitie van automatische titratie
- Gekleed om te doden:een pak op maat maken voor tumor-penetrerende kankermedicijnen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | French | Norway |

-
Wetenschap © https://nl.scienceaq.com
