Wetenschap
Automatische aanmaak van databases voor materiaalontdekking:innovatie uit frustratie
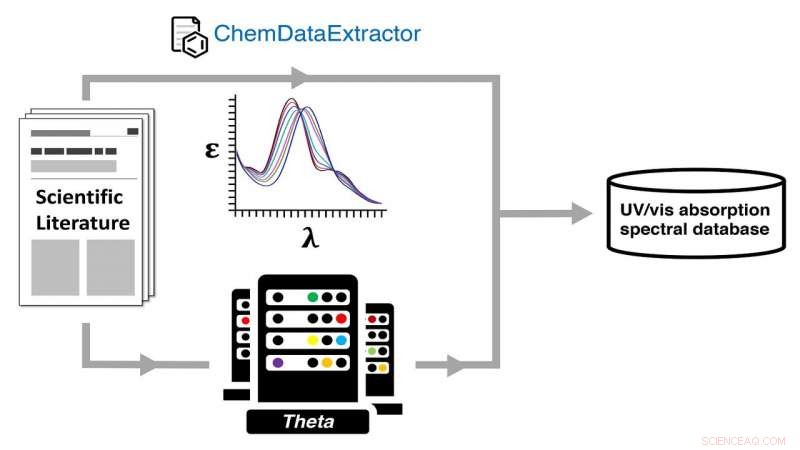
Automatisch genereren van een ultraviolet-zichtbare (UV-vis) absorptiespectrale database via een dubbele experimentele en computationele chemische gegevensroute met behulp van de Theta-supercomputer van ALCF. Krediet:Jacqueline Cole en Ulrich Mayer / Universiteit van Cambridge
Een samenwerking tussen de Universiteit van Cambridge en Argonne heeft een techniek ontwikkeld die automatische databases genereert om specifieke wetenschapsgebieden te ondersteunen met behulp van AI en high-performance computing.
Het doorzoeken van stapels wetenschappelijke literatuur naar bits en bytes aan informatie om een idee te ondersteunen of de sleutel te vinden om een specifiek probleem op te lossen, is al lang een vervelende aangelegenheid voor onderzoekers, zelfs na het begin van datagedreven ontdekkingen.
Jacqueline Cole kent de boor, maar al te goed. Hoofd Molecular Engineering aan de Universiteit van Cambridge, Verenigd Koninkrijk, ze heeft een groot deel van haar carrière besteed aan het zoeken naar materialen met optische eigenschappen die zich lenen voor een efficiëntere lichtverzameling, zoals kleurstofmoleculen die op een dag zonneramen kunnen aandrijven.
"Ik wist dat veel van de informatie in zeer gefragmenteerde vorm in de literatuur werd bewaard, " herinnert ze zich. "Maar als je duizenden en duizenden documenten verzamelde, dan zou je je eigen database kunnen vormen."
Dus Cole en collega's van Cambridge en het Argonne National Laboratory van het Amerikaanse Department of Energy (DOE) deden precies dat, het proces beschrijven in het journaal Wetenschappelijke gegevens .
De krant, zegt Cole, is een beschrijving van het bouwen van een database met behulp van natuurlijke taalverwerking (NLP) en high-performance computing, een groot deel van de laatste trad op in de Argonne Leadership Computing Facility (ALCF), een DOE Office of Science gebruikersfaciliteit.
Tot de factoren die de database uniek maken, behoren de schaal van het project en het feit dat het zowel experimentele als berekende gegevens over beide materiële structuren bevat, die de atomaire of chemische basis van een ding beschrijft, en materiaaleigenschappen, de functionaliteit die door die verschillende structuren wordt geboden.
"Het is waarschijnlijk de eerste compilatie van een database op zo'n enorme schaal, met 5, 380 like-for-like paren van experimentele en berekende gegevens, " zegt Cole. "En omdat het zo'n groot bedrag is, het dient als een op zichzelf staande opslagplaats en opent echt de deur naar het voorspellen van nieuwe materialen."
veel nieuwe, grote databases zijn puur gebaseerd op berekeningen, een inherent nadeel hiervan is dat ze niet worden gevalideerd door experimentele gegevens. Het laatste, misschien wel het meest significant, geeft een nauwkeurig beeld van de aangeslagen toestanden van het materiaal, die de dynamische toestand van elektronen definiëren en worden gebruikt om de functionele eigenschappen van een materiaal te berekenen:optische eigenschappen, in dit geval.
Deze ontluikende catalogus van aangeslagen toestanden kan vervolgens helpen bij het berekenen van de eigenschappen van materialen die nog moeten worden bedacht, verdere uitbreiding van de database.
"Stel je voor dat je een nieuw type optisch materiaal wilt ontdekken voor een op maat gemaakte functionele toepassing, en onze database bevat die specifieke optische eigenschap niet, " legt Cole uit. "We berekenen de optische eigenschap van belang uit de aangeslagen toestanden die beschikbaar zijn voor elke eigenschap in onze database, en maak een materiaal met op maat gemaakte functies."
Het team voerde kwantumchemische berekeningen uit op elke structuur waarvoor ze gegevens hadden geëxtraheerd over optische materialen, met behulp van de Theta-supercomputer van ALCF, dus het creëren van de database van gepaarde experimentele en berekende structuren en hun optische eigenschappen.
"Een van de grootste uitdagingen was het extraheren van chemische kandidaten die kunnen dienen als kleurstoffen voor zonnecellen uit 400, 000 wetenschappelijke artikelen, " zegt Álvaro Vázquez-Mayagoitia, een computationele wetenschapper in de Computational Science-divisie van Argonne. "We hebben een gedistribueerd raamwerk ontwikkeld om kunstmatige-intelligentiemethoden toe te passen, zoals die worden gebruikt in natuurlijke taalverwerking, op de supercomputers van wereldklasse van de ALCF."
Om die informatie automatisch te extraheren en in de database te deponeren, het team wendde zich tot de nieuwe datamining-applicatie ChemDataExtractor. Een NLP-tool, het is ontworpen om tekst specifiek te ontginnen vanuit de literatuur over scheikunde en materialen, waar, Cole zegt, "de informatie is verspreid over vele duizenden papieren en is aanwezig in zeer gefragmenteerde en ongestructureerde vormen."
Niet een voor handmatig zoeken naar artikelen, Cole omschrijft de drive om de applicatie te ontwikkelen als innovatie vanuit frustratie. aanvankelijk, ze probeerde meer generieke NLP-pakketten, maar merkte op dat "ze niet alleen falen, ze falen spectaculair."
Het probleem zit in de vertaling, niet zozeer vanuit het standpunt van de menselijke taal, maar uit de taal van de wetenschap, hoewel er enkele overeenkomsten zijn.
Een schrijver, bijvoorbeeld, zou een spraakherkenningsprogramma kunnen gebruiken, een vorm van NLP, om aantekeningen of interviews te transcriberen. Het programma traint voornamelijk op de stem van de schrijver, patronen en nuances oppikken, en begint vrij nauwkeurig te transcriberen. Gooi nu een interview in met een onderwerp met een buitenlands accent en de dingen beginnen wankel te worden.
In de wereld van Cole, de vreemde taal is wetenschap, elk domein een ander land. Momenteel, u hoeft het programma slechts op één "taal, "zeg scheikunde, en zelfs dan, je moet de specifieke dialecten van die wetenschap leren.
Anorganische scheikundigen zouden een formule kunnen opstellen met behulp van onbekende representaties van de bekende symbolen van chemische elementen, terwijl organische chemici de voorkeur geven aan chemische schetsen die genummerd zijn in een illustratiekader. De informatie van beide blijkt meestal te moeilijk voor de meeste mijnprogramma's om te extraheren.
"En dat zit gewoon in een beetje scheikunde, " merkt Cole op. "Omdat de manier waarop mensen dingen beschrijven zo divers is, diversiteit in domeinspecificiteit is absoluut cruciaal."
Daartoe, de database van het team is een van ultraviolet-zichtbare (UV/vis) absorptiespectrale attributen, die een open beschikbare bron biedt voor gebruikers die op zoek zijn naar materialen met spectrale kleuren die de voorkeur hebben.
Terwijl het team de nieuwe database gebruikt om organische kleurstoffen op te sporen die de traditionele metaal-organische kleurstoffen in zonnecellen zouden kunnen vervangen, ze hebben zich al op bredere fronten gericht voor het gebruik ervan.
Nuttig als bron van trainingsgegevens voor machinale leermethoden die nieuwe optische materialen voorspellen, het kan ook een eenvoudige optie zijn voor het ophalen van gegevens voor gebruikers van UV/vis-absorptiespectroscopie, een tool die veel wordt gebruikt in onderzoekslaboratoria over de hele wereld als een kerntechniek om nieuwe materialen te karakteriseren.
"De protocollen die in dit project worden gebruikt, worden al ingezet voor vergelijkbare soorten projecten, " voegt Vázquez-Mayagoitia toe. "Bijvoorbeeld, het team heeft onlangs ChemDataExtractor en ALCF-computerbronnen gebruikt om uitgebreide databases van potentiële batterijchemicaliën te produceren, en magnetische en supergeleidende verbindingen."
Het onderzoek naar de optische materialendatabase verschijnt in het artikel "Comparative dataset of experimentele and computational attributes of UV/vis Absorbtion Spectra" in Scientific Data. Andere auteurs zijn onder meer Edward J. Beard van de Universiteit van Cambridge, en Ganesh Sivaraman en Venkatram Vishwanath van het Argonne National Laboratory.
Een paper waarin hun werk met magnetische en supergeleidende materialen wordt beschreven, is gepubliceerd in: npj Computational Materials . De database met batterijmaterialen met meer dan 290, 000 datarecords zijn gepubliceerd in Wetenschappelijke gegevens .
 Luchtradar onthult grondwater onder gletsjer
Luchtradar onthult grondwater onder gletsjer- De natuurlijke habitat van olifanten
- Hoe te vertellen of een eekhoorn mannelijk of vrouwelijk is
- Verwaterde biodiversiteit:het type monster is van cruciaal belang in milieu-DNA-onderzoeken voor biomonitoring
- Unieke olie-etende bacteriën gevonden in diepste oceaangeul ter wereld
Hoofdlijnen
- Duurzaamheid van visserij gekoppeld aan genderrollen onder handelaren
- Geslachtsrollen in de oudheid
- Hoe een menselijke cel te maken voor een wetenschapsproject
- Een enzym dat de vorming van het DNA katalyseert Molecuul
- Wat zijn de biomoleculen van ribosomen?
- Bereken de percentages van adenine in een DNA-streng
- M-fase: wat gebeurt er in deze fase van de celcyclus?
- Nieuwe filmtechniek onthult bacteriële signalering in scherpere resolutie
- Hoe gedraag je je in een dierentuin - volgens de wetenschap
- Gemodificeerd enzym kan de productie van ethanol van de tweede generatie verhogen

- Onderzoekers ontwikkelen 3D-microstructuren die reageren op temperatuur en licht
- Een nieuwe manier om verspild methaan te benutten
- Nieuwe functionele biochar-composieten helpen afvalwater te behandelen

- Wetenschappers gebruiken moleculaire kettingen en chemische lichtsabels om platforms te bouwen voor tissue engineering

 Uitdunnen van bossen, voorgeschreven vuur vóór droogte verminderde boomverlies
Uitdunnen van bossen, voorgeschreven vuur vóór droogte verminderde boomverlies- Zeespiegelstijging:drie visies op een toekomstige zomervakantie aan de kust
- Vijftig jaar geleden, Jocelyn Bell ontdekte pulsars en veranderde onze kijk op het universum
- NASA-oproep voor astronauten trekt 12, 000 hoopvolle ruimtevluchten
- Wetenschappers tonen aan dat een veelbelovende vaste elektrolyt hydrofoob is
- Hoe leeuwenbekken hun kleur behouden:bewegwijzeringstruc onthult evolutionair mechanisme
- Ongekend brede en scherpe donkere materie kaart
- Studie bustes 9 tot 5 model voor academisch werk
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Swedish | German | Dutch | Danish | Portuguese | Norway |

-
Wetenschap © https://nl.scienceaq.com
