Wetenschap
Waarom taaltechnologie Game of Thrones (nog) niet aankan

Winterval. Krediet:mauRÍCIO santos (Unsplash, publiek domein)
Onderzoekers van de Vrije Universiteit Amsterdam en het Humanities Cluster van de KNAW evalueerden vier state-of-the-art tools voor het herkennen van namen in tekst, om hun prestaties op populaire fictie te beoordelen en te verbeteren. Ze vinden oplossingen om het vermogen van de tools om namen in één roman te herkennen, te vergroten van een nauwkeurigheid van 7% tot 90%.
Tools voor natuurlijke taalverwerking (NLP) worden vaak gebruikt in veel dagelijkse toepassingen zoals Siri en Google, maar de effectiviteit van deze technologieën wordt niet goed begrepen. Onderzoekers van de Vrije Universiteit Amsterdam en het Humanities Cluster van de Koninklijke Academie hebben een grondige evaluatie uitgevoerd van vier verschillende naamherkenningstools op populaire 40 romans, inclusief A Game of Thrones. Hun analyses, gepubliceerd in PeerJ Computerwetenschappen , markeer soorten namen en teksten die bijzonder uitdagend zijn voor deze tools om te identificeren, evenals oplossingen om dit te verminderen. In aanvulling, ze haalden sociale netwerken uit de romans om verschillen in verhaalstructuur te onderzoeken. Deze inzichten kunnen helpen om dergelijke technologieën robuuster te maken tegen genreverschillen, en kan bijvoorbeeld helpen deze technologie nuttiger te maken voor journalisten die grote datasets willen analyseren, zoals de Panama Papers.
Veel NLP-tools zijn gebaseerd op machine learning; dat is, een computerprogramma wordt getraind om patronen in tekst te herkennen op basis van eerder ingevoerde voorbeelden. Om namen in tekst te herkennen, het wordt bijvoorbeeld gevoed met veel krantenartikelen waarin mensen de namen minutieus hebben gemarkeerd. Het programma krijgt vervolgens de opdracht om te 'leren' hoe een naam eruitziet op basis van context (zoals het wordt voorafgegaan door de heer) of de vorm van het woord (zoals dat namen in het Engels meestal met een hoofdletter beginnen). Nutsvoorzieningen, het probleem bij het toepassen van een dergelijk systeem dat is getraind op kranten op romans, is dat romanschrijvers veel meer vrijheid hebben in hun verhaal dan journalisten die zich aan feiten moeten houden. Fictieschrijvers kunnen hun eigen naam verzinnen, zoals Tywin of R'hllor, of gebruik beschrijvende karakternamen rechtstreeks uit het woordenboek, zoals Gray Worm. Deze namen gedragen zich niet als 'gewone' namen, dus hebben NLP-systemen moeite om ze in een tekst te herkennen.
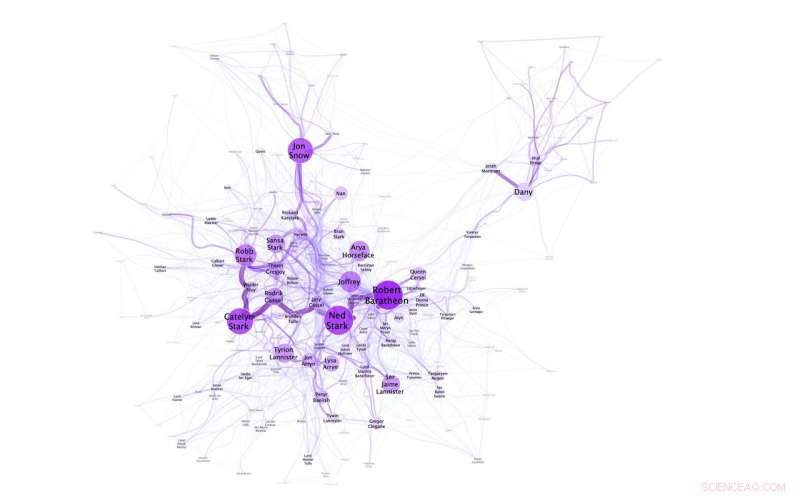
Netwerkvisualisatie die laat zien dat Dany/Daenerys niet in de buurt komt van andere hoofdpersonen in 'A Game of Thrones'. Credit:N.M. Dekker, CC BY-SA 4.0
De experimenten uitgevoerd door Niels Dekker (Trifork B.V.), Tobias Kuhn (Vrije Universiteit Amsterdam) en Marieke van Erp (KNAW Humanities Cluster) belichten ook de flexibiliteit van taal en hoe namen in verhalen worden gecontextualiseerd. Het is bijvoorbeeld mogelijk om naar Daenerys Targaryen te verwijzen als Daenerys en zij, maar ze is ook bekend als Dany, Daenerys Stormborn, Moeder der draken, Khaleesi, de Onverbrande en Mhysa. Het sociale netwerk gecreëerd voor A Game of Thrones, illustreert bijvoorbeeld dat Dany wordt gebruikt door haar vrienden, en haar volledige naam Daenerys alleen door haar vijanden (in haar afwezigheid).
Uit het in deze publicatie beschreven onderzoek blijkt dat er meer aandacht moet komen voor de performance van NLP-tools en dat er nog werk aan de winkel is voordat 'tekst' volledig door computers kan worden begrepen.
 Wetenschapsexperiment: Hoe melkzuur te maken
Wetenschapsexperiment: Hoe melkzuur te maken - Onderzoekers suggereren dat RNA en DNA hun oorsprong hebben gevonden in RNA-DNA-chimeren
- Radiale synthese is baanbrekend voor chemisch onderzoek en productie
- Wat gebeurt er als je Epsom-zouten en alcohol wrijft?
- Onderzoekers laten zien dat materialen vanzelf sterker worden wanneer ze met zeer hoge snelheid worden geraakt
- Duitsland zegt dat het de doelstelling voor 2020 heeft gehaald om de uitstoot van broeikasgassen te verminderen
- Grote gegevens, kunstmatige intelligentie ter ondersteuning van onderzoek naar schadelijke blauwalgen
- Cycloonfeiten voor kinderen
- NASA ziet vorming van tropische depressie Two-E in de oostelijke Stille Oceaan
- De juiste dosis geo-engineering kan de risico's van klimaatverandering verminderen, studie zegt:
Hoofdlijnen
- Malariaparasiet verpakt genetisch materiaal voor reis van muggen naar mensen
- Septate versus niet-Septate Hyphae
- Natuurbeschermers moeten het Hollywood-effect benutten om dieren in het wild te helpen
- Interacties tussen eenvoudige moleculaire mechanismen leiden tot complexe infectiedynamiek
- Wat is osmotische lyse?
- Sequentiebepaling van het genoom van stevia-planten voor het eerst onthuld
- Hoge prijzen van dierlijke producten onderdeel van een vicieuze cirkel naar uitsterven
- Hoe gedraag je je in een dierentuin - volgens de wetenschap
- Hoe spreken felle kleuren kinderen aan?





 Onderzoekers ontwikkelen recycling voor koolstofvezelcomposieten
Onderzoekers ontwikkelen recycling voor koolstofvezelcomposieten- Onderzoek levert doorbraken op in het begrijpen van falen van hoogwaardige vezels
- NASA's James Webb-ruimtetelescoop in het donker houden
- Slowaakse Wastebusters op kruistocht tegen zwerfvuil
- NASA-satellieten klaar wanneer sterren en planeten op één lijn liggen
- Een miniatuur laserachtig apparaat voor oppervlakteplasmonen
- Verjongend metaalglas om breuk te voorkomen
- Met augmented reality kunnen studenten een chemische fabriek besturen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
