Wetenschap
Is uw machine learning-trainingsset bevooroordeeld? Hoe nieuwe medicijnen te ontwikkelen op basis van samengevoegde datasets
Machine learning (ML)-algoritmen zijn slechts zo goed als de gegevens waarop ze zijn getraind. Als de trainingsset vertekend is, zal het ML-model ook vertekend zijn. Dit kan leiden tot onnauwkeurige voorspellingen en oneerlijke beslissingen.
Er zijn een aantal manieren waarop een trainingsset vertekend kan worden. Enkele van de meest voorkomende oorzaken zijn:
* Samplingbias: Dit gebeurt wanneer de trainingsset niet representatief is voor de populatie waarvoor het ML-model zal worden gebruikt. Als een trainingsset voor een gezichtsherkenningssysteem bijvoorbeeld alleen bestaat uit afbeeldingen van blanke mannen, zal het systeem minder nauwkeurig zijn in het herkennen van vrouwen en gekleurde mensen.
* Selectiebias: Dit gebeurt wanneer het gegevensverzamelingsproces bepaalde steekproeven bevoordeelt boven andere. Als een enquête bijvoorbeeld alleen wordt verzonden naar mensen die al interesse hebben getoond in een bepaald product, zullen de resultaten van de enquête een vertekend beeld geven van mensen die het product waarschijnlijk al zullen kopen.
* Meetafwijking: Dit gebeurt wanneer het gegevensverzamelingsproces fouten of vervormingen introduceert. Als een enquêtevraag bijvoorbeeld zo is geformuleerd dat mensen ertoe worden aangezet een bepaald antwoord te geven, zullen de resultaten van de enquête in de richting van dat antwoord neigen.
Het is belangrijk om u bewust te zijn van de mogelijke vooroordelen in ML-trainingssets en om stappen te ondernemen om deze te beperken. Enkele dingen die gedaan kunnen worden om vooroordelen te verminderen zijn onder meer:
* Een gevarieerde trainingsset gebruiken: De trainingsset moet gegevens uit verschillende bronnen bevatten en moet representatief zijn voor de populatie waarop het ML-model zal worden gebruikt.
* Onbevooroordeelde methoden voor gegevensverzameling gebruiken: Het gegevensverzamelingsproces moet zo worden ontworpen dat steekproefvertekening, selectievertekening en meetvertekening worden vermeden.
* Regelmatig de trainingsset controleren: De trainingsset moet regelmatig worden gecontroleerd om eventuele vooroordelen die erin zijn geslopen te identificeren en te corrigeren.
Door deze stappen te ondernemen, kunt u ervoor zorgen dat uw ML-modellen nauwkeurig en eerlijk zijn.
Hoe je nieuwe medicijnen kunt ontwikkelen op basis van samengevoegde datasets
Het samenvoegen van datasets kan een krachtige manier zijn om nieuwe medicijndoelen te identificeren en nieuwe medicijnen te ontwikkelen. Door gegevens uit verschillende bronnen te combineren, kunnen onderzoekers een uitgebreider inzicht krijgen in het ziekteproces en potentiële doelen identificeren die mogelijk over het hoofd zijn gezien als ze elke dataset afzonderlijk bekijken.
Er zijn een aantal uitdagingen verbonden aan het samenvoegen van datasets, waaronder:
* Heterogeniteit van gegevens: De datasets kunnen met verschillende methoden worden verzameld, verschillende formaten hebben en verschillende variabelen bevatten. Dit kan het moeilijk maken om de datasets op een zinvolle en nauwkeurige manier samen te voegen.
* Gegevenskwaliteit: De datasets kunnen fouten of ontbrekende gegevens bevatten. Dit kan het moeilijk maken om nauwkeurige conclusies te trekken uit de samengevoegde dataset.
* Gegevensprivacy: De datasets kunnen gevoelige informatie bevatten die moet worden beschermd. Dit kan het lastig maken om de samengevoegde dataset met andere onderzoekers te delen.
Ondanks deze uitdagingen kan het samenvoegen van datasets een waardevol hulpmiddel zijn voor de ontdekking van geneesmiddelen. Door de uitdagingen zorgvuldig aan te pakken, kunnen onderzoekers samengevoegde datasets creëren die kunnen leiden tot nieuwe inzichten en de ontwikkeling van nieuwe medicijnen.
Hier volgen enkele tips voor het ontwikkelen van nieuwe medicijnen op basis van samengevoegde datasets:
* Begin met een duidelijke onderzoeksvraag. Wat hoop je te leren van de samengevoegde dataset? Dit zal u helpen uw inspanningen voor het verzamelen en analyseren van gegevens te concentreren.
* Identificeer en verzamel de relevante datasets. Zorg ervoor dat de datasets relevant zijn voor jouw onderzoeksvraag en dat ze de data bevatten die jij nodig hebt.
* Beoordeel de gegevenskwaliteit. Controleer de datasets op fouten en ontbrekende gegevens. Zorg ervoor dat de gegevens nauwkeurig en betrouwbaar zijn.
* De datasets samenvoegen. Er zijn een aantal verschillende manieren om datasets samen te voegen. Kies de methode die het meest geschikt is voor uw gegevens.
* Analyseer de samengevoegde dataset. Gebruik statistische en machine learning-methoden om de samengevoegde dataset te analyseren. Zoek naar patronen en trends die kunnen wijzen op nieuwe doelwitten voor medicijnen.
* Valideer uw bevindingen. Voer experimenten uit om uw bevindingen te valideren. Zorg ervoor dat de nieuwe medicijndoelen daadwerkelijk effectief zijn bij de behandeling van de ziekte.
Door deze tips te volgen, kunt u uw kansen vergroten om nieuwe medicijnen te ontwikkelen op basis van samengevoegde datasets.
 Chemici synthetiseren miljoenen eiwitten die niet in de natuur voorkomen
Chemici synthetiseren miljoenen eiwitten die niet in de natuur voorkomen- Warmte en licht creëren nieuwe biocompatibele microdeeltjes
- Een nieuw recyclingproces voor polystyreen zou de eerste ter wereld kunnen zijn die zowel economisch als energiezuinig is
- Wetenschappers ontdekken hoe oppervlakken het vroege leven op aarde hebben kunnen helpen beginnen
- Nieuwe aanpak kan autoriteiten helpen sneller te reageren op radiologische dreigingen in de lucht
- Het Duitse kabinet tekent plannen af om CO2-afvang mogelijk te maken
- De krachten achter de extreem hete zomer in Zuid- en Centraal-China
- Wat zijn de voordelen van Parthenogenesis?
- Welke informatie kunnen wetenschappers krijgen van fossielen?
- Uit onderzoek blijkt dat radontestkits voor de korte termijn niet effectief zijn bij het meten van blootstelling aan radongas
Hoofdlijnen
- Hoe is DNA geordend om in een cel te passen?
- Hoe maak je een werkend hart Model
- Hoe UEA-onderzoek zou kunnen helpen bij het bouwen van computers uit DNA
- Waar gaan microplastics naar de oceanen?
- Vingerafdrukexperimenten
- Kunnen katten op een plaats delict helpen bij het vinden van belangrijk DNA-bewijs?
- Waarom leven sommige planten snel en sterven ze jong?
- Wetenschappers ontdekken hoe een groep rupsen giftig werd
- Kunnen boerderijen maximaal produceren en toch de uitstoot van broeikasgassen verminderen?
- Onderzoekers demonstreren infraroodlichtmodulatie met grafeen
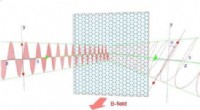
- Grafeen blijkt infrarood licht uit te zenden

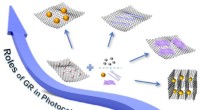
- Multifunctionele op grafeen gebaseerde composieten, georiënteerd op rollen van grafeen in fotokatalyse
- Door het kijkglas op nanoschaal:bepaling van bosonpiekfrequentie in ultradun aluminiumoxide

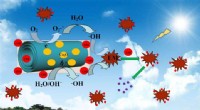
- Verbeterde fotokatalytische activiteit door Cu2O nanodeeltjes geïntegreerde H2Ti3O7 nanobuisjes

 Hoe evolutie werkt
Hoe evolutie werkt - Structuur van het hart Cell
- Hoe Tear Gas te maken
- Stadsvaren, plattelandsvaren:burgerwetenschap helpt onderzoeken waarom sommige planten van het stadsleven houden
- Open-source software simuleert rivier- en afvoerbronnen
- Plastic in rivieren belangrijkste bron van oceaanvervuiling:studie
- Een 100-voudige sprong naar GigaDalton DNA nanotech
- Licht aan het einde van de nanotunnel voor toekomstige katalysatoren
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
