Wetenschap
Deep learning breidt onderzoek naar sanering van nucleair afval uit
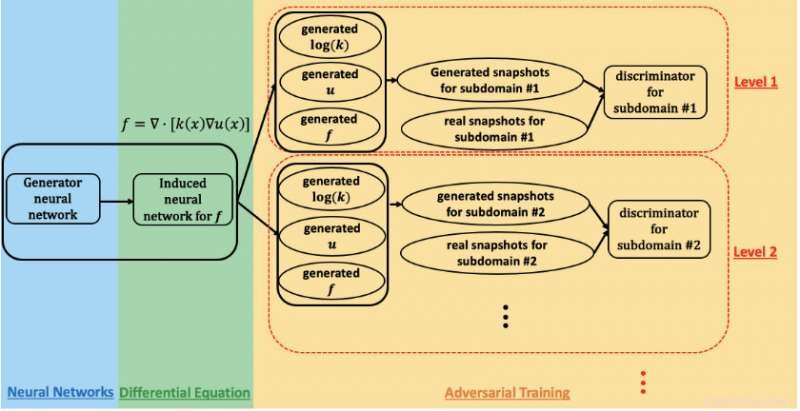
Een schema van het fysica-geïnformeerde generatieve vijandige netwerk dat wordt gebruikt om parameters te schatten en de onzekerheid in de ondergrondse stroom op de Hanford-site te kwantificeren. Krediet:Prabhat, Lawrence Berkeley National Laboratory
Een onderzoekssamenwerking tussen Lawrence Berkeley National Laboratory (Berkeley Lab), Pacific Northwest National Laboratory (PNNL), bruine universiteit, en NVIDIA heeft exaflop-prestaties bereikt op de Summit-supercomputer met een deep learning-toepassing die wordt gebruikt om ondergrondse stroming te modelleren in de studie van de sanering van nucleair afval. Hun prestatie, die zal worden gepresenteerd tijdens de workshop "Deep Learning on Supercomputers" op SC19, demonstreert de belofte van fysica-geïnformeerde generatieve adversariële netwerken (GAN's) voor het analyseren van complexe, grootschalige wetenschappelijke problemen.
"In de wetenschap kennen we de wetten van de fysica en observatieprincipes - massa, momentum, energie, enzovoort., " zei George Karniadakis, hoogleraar toegepaste wiskunde bij Brown en co-auteur van de SC19 workshoppaper. "Het concept van fysica-geïnformeerde GAN's is om voorafgaande informatie van de fysica in het neurale netwerk te coderen. Hierdoor kun je veel verder gaan dan het trainingsdomein, wat erg belangrijk is in toepassingen waar de omstandigheden kunnen veranderen."
GAN's zijn toegepast om het uiterlijk van het menselijk gezicht met opmerkelijke nauwkeurigheid te modelleren, merkte Prabhat op, een co-auteur van de SC19-paper die leiding geeft aan het Data and Analytics Services-team van het National Energy Research Scientific Computing Center van Berkeley Lab. "In de wetenschap, Berkeley Lab heeft de toepassing van vanille-GAN's onderzocht voor het creëren van synthetische universums en deeltjesfysica-experimenten; een van de openstaande uitdagingen tot nu toe was het opnemen van fysieke beperkingen in de voorspellingen, " zei hij. "George en zijn groep bij Brown hebben een pioniersrol gespeeld in de benadering van het opnemen van natuurkunde in GAN's en deze te gebruiken om gegevens te synthetiseren - in dit geval, ondergrondse stroomvelden."
Voor deze studie is de onderzoekers concentreerden zich op de Hanford-site, opgericht in 1943 als onderdeel van het Manhattan-project om plutonium voor kernwapens te produceren en uiteindelijk de thuisbasis van de eerste volledige plutoniumproductiereactor ter wereld, acht andere kernreactoren, en vijf plutonium-verwerkingscomplexen. Toen de plutoniumproductie in 1989 eindigde, achtergelaten waren tientallen miljoenen gallons radioactief en chemisch afval in grote ondergrondse tanks en meer dan 100 vierkante mijl verontreinigd grondwater als gevolg van de afvoer van naar schatting 450 miljard gallons vloeistoffen naar stortplaatsen voor grond. Dus de afgelopen 30 jaar heeft het Amerikaanse ministerie van Energie samengewerkt met de Environmental Protection Agency en het Washington State Department of Ecology om Hanford op te ruimen, die is gelegen op 580 vierkante mijl (bijna 500, 000 acres) in het zuiden van het centrum van Washington, hele delen ervan grenzend aan de Columbia-rivier - de grootste rivier in de Pacific Northwest en een cruciale verkeersader voor industrie en dieren in het wild.
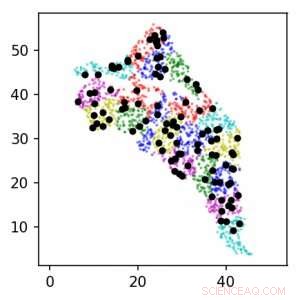
Met behulp van fysica-geïnformeerde GAN's op de Summit-supercomputer, het onderzoeksteam was in staat om parameters te schatten en de onzekerheid in ondergrondse stroming te kwantificeren. Deze afbeelding toont locaties van sensoren rond de Hanford-site voor niveaus 1 (zwart) en 2 (kleur). Eenheden zijn in km. Krediet:Lawrence Berkeley National Laboratory
Om de opruiminspanning te volgen, werknemers vertrouwden op het boren van putten op de Hanford-locatie en het plaatsen van sensoren in die putten om gegevens te verzamelen over geologische eigenschappen en grondwaterstroming en om de voortgang van verontreinigingen te observeren. Ondergrondse omgevingen zoals de Hanford-site zijn zeer heterogeen met variërende ruimte-eigenschappen, verklaarde Alex Tartakovsky, een computationele wiskundige bij PNNL en co-auteur van het SC19-papier. "Het schatten van de eigenschappen van Hanford Site op basis van alleen gegevens zou meer dan een miljoen metingen vergen, en in de praktijk hebben we er misschien wel duizend. De wetten van de fysica helpen ons het gebrek aan gegevens te compenseren."
"De standaard benadering voor het schatten van parameters is om aan te nemen dat de parameters veel verschillende vormen kunnen aannemen, en dan moet je voor elke vorm ondergrondse stroomvergelijkingen misschien wel miljoenen keren oplossen om parameters te bepalen die het beste bij de waarnemingen passen, " voegde Tartakovsky toe. Maar voor deze studie nam het onderzoeksteam een andere weg in:met behulp van een fysica-geïnformeerde GAN en high-performance computing om parameters te schatten en onzekerheid in de ondergrondse stroom te kwantificeren.
Voor dit vroege validatiewerk, de onderzoekers kozen ervoor om synthetische gegevens te gebruiken - gegevens die zijn gegenereerd door een berekend model op basis van deskundige kennis over de Hanford-site. Hierdoor konden ze een virtuele weergave van de locatie maken die ze vervolgens naar behoefte konden manipuleren op basis van de parameters die ze wilden meten - voornamelijk doorlatendheid en verval, beide zijn essentieel voor het modelleren van de locatie van de verontreinigingen. Toekomstige studies zullen echte sensorgegevens en omstandigheden in de echte wereld opnemen.
"Het oorspronkelijke doel van dit project was om de nauwkeurigheid van de methoden in te schatten, dus gebruikten we synthetische gegevens in plaats van echte metingen, Tartakovsky zei. "Hierdoor konden we de prestaties van de fysica-geïnformeerde GANS schatten als een functie van het aantal metingen."
Bij het trainen van de GAN op de Summit-supercomputer bij de Oak Ridge Leadership Computing Facility OLCF, het team was in staat om 1,2 exaflop-piek en aanhoudende prestaties te bereiken - het eerste voorbeeld van een grootschalige GAN-architectuur die werd toegepast op SPDE's. De geografische omvang, ruimtelijke heterogeniteit, en meerdere correlatielengteschalen van de Hanford-site vereisten het trainen van het GAN-model tot duizenden dimensies, dus ontwikkelde het team een sterk geoptimaliseerde implementatie die opschaalde naar 27, 504 NVIDIA V100 Tensor Core GPU's en 4, 584 nodes op Summit met een schaalefficiëntie van 93,1%.
"Het bereiken van zo'n enorme schaal en prestaties vereiste volledige stack-optimalisatie en meerdere strategieën om maximaal parallellisme te verkrijgen, " zei Mike Houston, die het AI Systems-team bij NVIDIA leidt. "Op chipniveau we hebben de structuur en het ontwerp van het neurale netwerk geoptimaliseerd om het gebruik van Tensor Core te maximaliseren via cuDNN-ondersteuning in TensorFlow. Op knooppuntniveau, we gebruikten NCCL en NVLink voor snelle gegevensuitwisseling. En op systeemniveau we hebben Horovod en MPI geoptimaliseerd, niet alleen om de gegevens en modellen te combineren, maar ook om parallelle strategieën van tegenstanders aan te kunnen. Om het gebruik van onze GPU's te maximaliseren, we moesten de gegevens sharden en vervolgens distribueren om af te stemmen op de parallellisatietechniek."
"Dit is een nieuw hoogtepunt voor GAN-architecturen, "Zei Prabhat. "We wilden een goedkope surrogaat creëren voor een zeer kostbare simulatie, en wat we hier hebben kunnen laten zien, is dat een door fysica beperkte GAN-architectuur ruimtelijke velden kan produceren die consistent zijn met onze kennis van de natuurkunde. In aanvulling, dit voorbeeldproject bracht experts van ondergrondse modellering samen, toegepaste wiskunde, diep leren, en HPC. Aangezien de DOE bredere toepassingen van diep leren beschouwt - en, vooral, GAN's - tot simulatieproblemen, Ik verwacht dat meerdere onderzoeksteams zich door deze resultaten zullen laten inspireren."
De krant, "Zeer schaalbaar, Natuurkundig geïnformeerde GAN's voor leeroplossingen van stochastische PDE's, " zal worden gepresenteerd tijdens de SC19 Deep Learning on Supercomputers-workshop. I
 Een stap dichter bij een waterstofeconomie met een efficiënte anode voor het splitsen van water
Een stap dichter bij een waterstofeconomie met een efficiënte anode voor het splitsen van water- "What Are Oxidants?
- Een technologie voor drukloze sinterverbinding voor vermogenshalfgeleiders van de volgende generatie
- een nieuwe, snellere manier om diblock-polymeermaterialen te verwerken
- Ontkoppeling van elektronisch en thermisch transport
- Vuurvliegjes levend houden
- Onderzoekers beweren dat langdurige blootstelling aan luchtvervuiling in China tussen 2000 en 2016 30,8 miljoen mensen heeft gedood
- Tropische droge bosplanten
- Trump zei seismische tests voor olie in Atlantische wateren door te voeren
- Wetenschappers produceren radioactiviteitvrije Tsjernobyl-wodka
Hoofdlijnen
- Onderzoekers bestuderen de pathobiologie van antibiotische nevenreacties
- Celwand: definitie, structuur en functie (met diagram)
- Een konijn ontleden
- Music Science Fair Project Ideas
- Drie van de meest bizarre relaties van de natuur
- Wat zijn de belangrijkste functies van Cilia & Flagella?
- Computerprogramma detecteert verschillen tussen menselijke cellen
- Septate versus niet-Septate Hyphae
- Ideeën voor een Sunscreen Science Fair Project
- Kunstmatige intelligentie ontwerpt metamaterialen die worden gebruikt in de onzichtbaarheidsmantel
- Onderzoekers identificeren universele wetten in het turbulente gedrag van actieve vloeistoffen

- Een gedenkwaardige kijk op de geboorte van foto-elektronen

- Wervelende zwermen bacteriën bieden inzicht in turbulentie
- Fotovoltaïsche perovskieten kunnen neutronen detecteren


 Onderzoekers ontwikkelen een goedkope, gerichte antibacteriële verbinding
Onderzoekers ontwikkelen een goedkope, gerichte antibacteriële verbinding- Uit angst voor een no-deal Brexit, Britse autofabrikanten remmen investeringen af
- NASA stuurt E. coli de ruimte in voor de gezondheid van astronauten
- Wat zijn fysieke kenmerken die worden overgegeven van ouders?
- Afvalsilicium krijgt nieuw leven in lithium-ionbatterijen
- Met suiker bekleed nanomateriaal blinkt uit in het bevorderen van botgroei
- Lijst van het gebruik voor magneten
- De effecten van zuur op verschillende soorten metaal
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
